20251128论文学习
Effective Directed Fuzzing with Hierarchical Scheduling for Web Vulnerability Detection
Abstract
该工作提出了一种新的定向Fuzzing方法,称为WDFUZZ,它可以有效地审查Java Web应用程序的安全性。解决了两个主要的挑战:(1)有效地探索大量的网页条目和参数;(2)生成结构化和语义受限的输入。WDFUZZ方法是两重的。首先,开发了一种语义约束提取技术,以准确地捕获Web参数的预期输入结构和约束。 其次,实现了一种分层调度策略,该策略评估每个种子触发漏洞的潜力,并对最有希望的种子进行优先级排序。在对15个真实Java Web应用的评估中,WDFUZZ取得了92.6%的召回率,在已知漏洞数据集中发现3.2倍以上的漏洞并对其进行检测比目前最先进的网络模糊器快7.1倍。还发现了92个先前未知的漏洞,其中4个CVE和15个CNVD。
Introduction
挑战1:有效地探索大量的网页条目和参数。Web应用程序通常具有较大的代码空间,其中包含大量的入口点和参数。在实际应用中,这种多维度的大搜索空间使得高效地定位漏洞变得困难。
挑战2:生成结构化和语义受限的输入。Web应用程序通常需要具有特定语义约束的复杂、结构化的输入来进行彻底的测试。这些输入很难用传统的模糊测试方法生成,使得有效地发现漏洞具有挑战性。
为了应对这些挑战,已经做出了一些努力。然而,他们面临的弱点阻碍了他们识别Java Web应用程序中的漏洞的有效性。黑盒网络扫描器[2(burpsuite)、5(zap)、23(ReScan)、24(Black Widow)]由于依赖日益复杂的网络前端交互来获取反馈,往往难以达到低覆盖率,无法充分挖掘更深层次的漏洞。灰盒网页模糊测试[27(Experience)、28(Atropos)、38(phuzz)、42(witcher)、45(webFuzz)、49(Cefuzz)]也表现出严重的局限性。由于采用了基于覆盖率的指导,他们往往会探索大量与漏洞无关的代码。同时,它们简单的调度策略未能识别和优先触发漏洞的最有希望的Web入口点,反而浪费了时间和预算在不太可能的候选上,最终降低了漏洞检测的整体效率。此外,这些方法通常依赖于不完整的黑盒爬虫来提取网页参数,忽略了输入的结构化性质及其语义约束,进一步限制了它们生成有效测试用例的能力。
本文提出了一种新的模糊器WDFUZZ,它可以有效地检测Java Web应用程序中的命令注入、SQL注入和任意文件读写方法等6种常见的关键漏洞。我们的方法受到几个关键见解的启发,这些见解有助于解决探索广泛的代码空间和生成具有语义约束的结构化输入的固有挑战。
首先,尽管在一个Web应用中存在大量的入口点,但实验结果表明,只有4.8%的网页条目涉及安全敏感操作,具有触发网页漏洞的潜力。一个自然的想法是,可以利用有向模糊测试来缩小待分析的代码空间。 为了实现这一点,在连接用户输入(通过切入点)到敏感操作的关键路径上引导fuzz是至关重要的。
其次,由于应用程序的不同部分所使用的输入验证、净化和处理逻辑的级别不同,在不同的Web入口点和接收器位置上触发漏洞的难度也不同。这种差异促使我们设计一种新颖的分级调度策略,将测试资源优先分配到最有前途的路径上,最大限度地提高成功利用的可能性。
基于这些见解,我们设计了WDFUZZ,包括两个主要阶段
- 静态准备,它理解和提取必要的语义,包括对sink的敏感路径和路径约束,以进一步指导模糊测试;
- 动态fuzzing,采用分层调度策略进行路径探索。
具体来说,在静态准备阶段,WDFUZZ执行入口和汇发现,以确定关键的代码区域。然后,WDFUZZ进行脆弱路径提取,以识别潜在的利用路径和语义约束提取来指导模糊测试。具体来说,WDFUZZ收集输入参数的必要信息,最终构建一个准确反映输入数据的结构和约束的请求树。
在第二个模糊测试阶段,我们提出了一种分层调度策略来评估和优先考虑最有希望用于模糊测试的种子。然后将选择的种子进行变异以生成Web请求,并针对Web应用程序执行以收集距离反馈,以评估对脆弱路径的探索。任何触发缺陷预言的请求都记录在一个全面的漏洞报告中。因此,WDFUZZ策略性地瞄准了高风险的代码区域,显著地提高了Java Web应用程序漏洞检测的效率。
最后,我们在一个由15个广泛使用的流行Java Web应用程序(包括开源的应用程序和闭源的商业应用程序)和68个已知漏洞组成的多样化数据集上评估了WDFUZZ的有效性和效率。WDFUZZ取得了令人瞩目的92.6 % (63/68)的已知漏洞召回率,是witcher的3.2倍。此外,WDFUZZ还显著降低了漏洞的暴露时间(TTE),达到了87.69%,与witcher相比降低了69%。在漏洞检测效率方面,WDFUZZ每小时可以识别59.39个漏洞,比witcher快1倍。 此外,WDFUZZ成功识别了92个以前未知的漏洞。
Background and Motivation
近年来,Web应用漏洞检测主要采用静态分析、黑盒扫描和灰盒模糊测试3种方法。尽管这些工作在该问题领域取得了不错的初步成果,但它们仍然具有不可忽略的局限性,这极大地损害了漏洞检测的有效性和效率。
静态分析技术(e.g., TChecker,ANTaint和JackEE)已经被开发出来,用于自动分析源代码中潜在的安全缺陷。其主要思想是将恶意用户输入从Web入口点追踪到一些安全敏感的操作,以发现Web应用中潜在的脆弱执行路径。这些技术的一个共同的已知问题是高误报率,它花费大量的人工干预来分析bug报告以发现真正的安全威胁。此外,静态方法难以生成实用的概念证明(PoC)漏洞,限制了它们在实际场景中的可用性,例如验证和修复检测到的漏洞。
黑盒扫描器(e.g., Burp Suite,Wapiti和OWASP ZAP)专注于在不访问底层代码的情况下测试正在运行的Web应用程序。虽然这些扫描器有助于从攻击者的角度识别漏洞,但它们通常覆盖率较低,无法在应用程序中探索更深层次的漏洞。它们的有效性进一步受限于依赖复杂的前端交互来收集反馈,这可能不足以代表所有潜在的攻击向量。
灰盒模糊测试通过结合动态和静态分析技术来利用程序的内部信息来提高漏洞检测效率,已成为一种很有前途的方法。与传统的静态和黑盒方法相比,它具有显著的优势,使其成为测试Web应用程序的一个有吸引力的选择。在这个领域中,已经开发了多种技术,如webFuzz[45],witcher[42],Atropos[28]和CeFuzz[49]。然而,这些方法仍然无法解决关键挑战,限制了它们在检测漏洞方面的有效性。现有方法主要依靠黑盒爬虫产生初始种子,往往导致攻击面发现不完整,漏报率较高。此外,它们通常使用覆盖率引导的反馈,这效率低下,并且在没有导致漏洞的分支上浪费时间。Web应用参数的嵌套结构和复杂的语义约束也使得这些方法难以生成有效的测试用例。这些局限性突出表明,迫切需要一种更有效的模糊测试方法来增强Web应用程序中的漏洞检测,本文将对此进行探讨。
WDFUZZ Overview
为了提高Web应用程序的安全性,我们必须解决一个关键问题:如何有效地对Web应用程序进行模糊测试来发现漏洞。正如前面章节所讨论的,由于Web应用程序的复杂性和庞大的代码空间,覆盖率引导的模糊测试方法是不充分的。这就需要采用定向模糊测试,这使得我们可以策略性地剪枝搜索空间。此外,与二进制程序中的内存损坏漏洞不同,内存操作无处不在,发现潜在的脆弱操作具有挑战性,Web漏洞与特定的安全敏感操作密切相关,例如数据库操作和网络请求。 这些操作可以通过静态分析更容易地识别,使其成为定向模糊处理的合适目标。因此,使用定向模糊测试对于提高Web应用程序的漏洞检测效率是非常有帮助和必要的。尽管定向模糊测试并不是一个新颖的概念,并且已经成功应用于模糊二进制软件,但在Web应用漏洞检测的背景下,定向模糊测试仍然面临着独特的挑战。
Challenges
模糊测试是最有效的漏洞检测方法之一。为了将模糊测试应用于Web应用的安全,必须解决两个主要的挑战:
- 如何在吞吐量限制下有效地探索Web条目和参数;
- 如何解决嵌套结构和复杂语义对Web应用输入的限制。
挑战1:探索大量低吞吐量的网页条目和参数。
第一个挑战是在Web应用程序中探索大量的入口点和参数,再加上测试吞吐量低。Web应用程序通常暴露成百上千个入口点,每个入口点往往需要多个参数进行测试。例如,一个商业的Java Web应用程序可以提供超过27,000个可访问的入口点,每个入口点平均有10个输入参数。即使我们使用静态分析对不太可能触发漏洞的条目点进行剪枝,仍然有超过1200个条目,代表着很大的探索空间。
此外,模糊测试Web应用程序的吞吐量非常低,通常低于15 execs/s,而二进制程序模糊测试通常达到500 execs/s以上。现有的研究也表明,Web应用的吞吐量可以下降到1.25 execs/s。这种模糊测试吞吐量的显著降低限制了在合理的时间预算内探索和测试Web应用程序的能力。
挑战2:生成结构化和语义约束的输入来测试网页参数。
许多Web应用需要复杂格式的输入,如JSON或XML,这些输入由嵌套的键值对组成。这种结构复杂性给模糊测试带来了巨大的挑战,因为它很难推断出合适的键和值,以及满足程序要求的整体结构。因此,生成能够被应用程序准确处理的格式良好的请求成为一项艰巨的任务。
此外,Web应用程序往往对这些输入施加严格的语义约束,例如日期和电子邮件地址等特定格式,以及应用程序代码中的约束。这些限制使得输入的生成过程更加复杂,因为输入不仅要符合所需的结构,而且还要具有应用的期望值。由于无法生成有效且有意义的输入,这极大地限制了模糊器在发现Web应用漏洞方面的有效性。
示例:

图1a展示了一个Java Web应用程序中涉及多个Web入口点和两个sink位置(即执行安全敏感操作的代码位置)的实例。Java方法 deptMapper.updateDept 和 deptMapper.deleteDept 在第10行和第15行是潜在的SQL注入sink,因为底层数据库操作的配置使用了不安全的 ${params.dataScope} 占位符,直接将参数值注入到SQL语句(图1b中第3行)中。
检测如图1所示的漏洞是具有挑战性的。首先,在本例中的所有代码路径中,只有以红色突出显示的路径–从入口点1 (第2行的 edit 方法)到sink点1 (第10行 deptMapper.updateDept 方法)–是可利用的。现有的工作通常采用简单的固定调度策略,统一探索所有的网页条目,浪费了大量的时间在不能触发漏洞的不希望出现的条目上。例如,在这个例子中,入口2是不脆弱的,因为外部配置 config.allowDelete 被设置为假。
此外,现有的解决方案可能无法生成有效的和有意义的输入。在这个例子中,触发漏洞的有效载荷必须满足以下结构和语义约束:(1)输入语义:输入必须遵守复杂的验证,如电子邮件和数据格式,以确保Web应用程序接受所提供的输入。(2)输入结构:参数必须遵循嵌套结构。例如,params 参数必须是包含一个名为 action 的键的map,其值必须是一个结构化的JSON字符串。这个JSON必须具有用于修改或删除的嵌套键,并且这两个键的值必须为布尔值true。(3)应用检查:status 字段必须是 open,以便对 edit 过程进行必要的过关检查。
现有的模糊测试几乎无法提取这些语义约束,并且通常无法生成在现代Web应用中普遍存在的有效嵌套结构的输入,如maps和JSON。
Our Main Idea
针对上述挑战,我们的主要思想是应用定向模糊测试,将有限的测试资源集中在Web应用程序的高风险代码区域,从而最大限度地提高漏洞检测的效率。然而,正如前面所讨论的那样,仍然有一些困难需要解决。通过对Web应用特点的观察,我们总结了以下几个关键的见解,这些见解有助于我们设计一个有效的定向模糊器。
#1:不同的web入口点和sink位置触发漏洞的困难程度不同。一些入口点及其相关的汇点位置可能比其他更容易被利用。通过识别这种差异,我们可以将更多的测试资源分配给那些更有可能产生成功利用的位置。我们设计了一种新颖的分层调度技术来识别最有希望的条目、接收器位置和种子,并对它们进行优先级排序,从而最大限度地发现Web应用程序中的漏洞。
#2:Web应用开发通常涉及使用知名的框架和库来配置可访问的入口点和处理用户输入。例如,据统计,Spring框架占据了Java服务器端Web应用81%的市场份额。因此,这种流行的开发模式能够有效地提取Web入口点和处理输入的API序列,这有助于理解Web应用程序的预期输入。重要的是,这些API序列包含了关于输入的广泛信息,包括数据类型、嵌套关系和验证规则,从而提供了对参数之间关系及其预期格式的洞察。
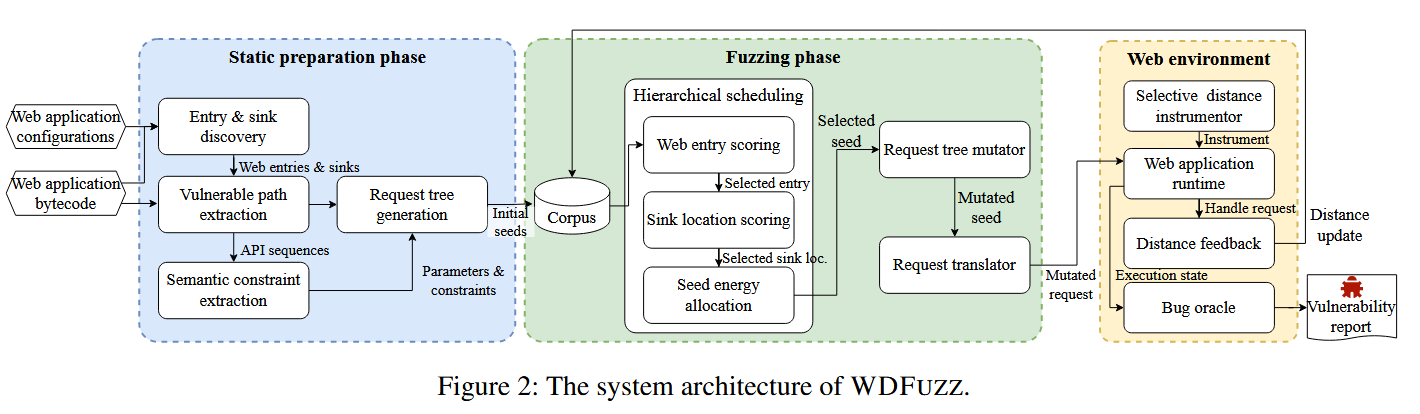
如图2所示,WDFUZZ的整体流程包括两个主要阶段:静态准备阶段和模糊测试阶段。
静态准备阶段
WDFUZZ以目标Web应用的字节码和配置文件作为输入。静态准备阶段从入口和汇点发现开始,识别Web应用中所有的入口点和汇点调用站点。然后WDFUZZ通过静态分析进行脆弱路径提取,识别从表项到sink的潜在脆弱路径。这些路径后来可以用于精确提取约束和构造初始种子。
然后,基于脆弱路径上的API序列进行语义约束提取,获取输入参数的结构和约束信息。通过使用Web应用开发模式,我们可以系统地开发精确的语义约束提取技术,实现对Web参数的结构(例如嵌套的JSON对象)和语义约束(如电子邮件、日期格式、应用程序代码中的检查等)的推断。
这些信息共同作用于请求树的生成,其中模糊测试的初始种子是基于树的表示生成的,准确地反映了输入参数的结构和约束。此外,静态准备阶段还为Web应用程序运行时的距离插桩提供信息。
模糊测试阶段
静态准备阶段结束后,将生成的初始种子放入语料库中。WDFUZZ采用分层调度技术,根据多个因素评估web入口、sink位置和种子的潜力,从而优先考虑最有希望发现漏洞的种子。这种有针对性的方法确保了WDFUZZ首先关注最有前途的种子,提高了我们的模糊处理过程的效率和效果。
然后使用请求树变异器对选择的种子进行变异,并翻译成变异后的请求来测试Web应用。在运行时,执行这些变异的请求,并收集距离反馈来评估模糊测试在探索脆弱路径方面的进展。这种反馈有助于判断一个种子是否足够”有趣”,以保证进一步的突变,并为未来对种子的评估提供信息。最后,报告任何触发bug oracle的请求,并生成一个全面的漏洞报告,对发现的问题进行详细说明。
Design and Implementation
Static Preparation Phase
在这个阶段,我们的目标是识别Web应用程序中的脆弱代码区域,并提取相应的Web参数结构和约束。该工作流程包括入口点和汇点的发现、脆弱路径的提取以及与输入参数相关的语义约束的识别。
Entry and Sink Discovery
为了静态地发现Web应用内部的脆弱路径,第一步是定义和检测应用中可行的入口和汇,由于Web应用架构的复杂性和多变性,这具有挑战性。我们的主要见解源于观察到,大多数(超过81%)的Java Web应用程序是使用成熟的Web框架(如Servlet和Spring框架)开发的。通过利用这种洞察力,WDFUZZ结合了一种方法,系统地匹配这些框架固有的共同开发模式,以有效地识别对定向模糊测试至关重要的web入口点和sink位置。
入口点识别。检测Web应用入口点的目标是识别尽可能多的攻击向量,这对于发现更多的漏洞至关重要。我们根据五种流行的Java Web框架的文档,包括Spring1,Struts22,Servlet3,JSP4和Javax标准的REST APIs5,全面地构建了它们的开发模式。如图1a中的例子,WDFUZZ能够识别作为Web入口点的编辑和删除,因为它的路径是由Spring框架中的@PostMapping(第1、17行)注释明确定义的。
sink识别。WDFUZZ采用两种主要策略来识别sink和寻找sink位置。首先,WDFUZZ依赖于一个人工预定义的sink列表,包括常见的安全敏感操作如SQL执行、命令执行、SSRF等。这些预定义的sink,如附录A所列,来源于Web应用安全中的著名模式和实践,确保我们的分析涵盖了Web漏洞可能发生的最关键的领域。
其次,WDFUZZ还融入了互补的sink识别策略,以准确识别运行时引入的sink。其必要性在于,Java Web应用程序中的一些安全敏感操作仅在运行时被观察到。例如,用于数据库操作的MyBatis6和用于模板渲染的Thymeleaf7等框架可以在应用程序执行过程中将敏感操作绑定到用户自定义的Java方法。具体来说,WDFUZZ依赖于从框架文档中导出的一组静态检测规则来识别这些运行时sink。例如,WDFUZZ通过应用静态检测规则分析图1b中的SQL映射配置,可以将 deptMapper.updateDept 识别为执行SQL操作的sink。
Vulnerable Path Extraction
该模块旨在通过污点分析高效地识别和提取脆弱路径。提取脆弱路径的过程不仅包括从web输入到sink位置的路径跟踪,还包括沿着这些路径跟踪用户输入的web参数,以确定这些输入是否可以影响任何sink。WDFUZZ提取了那些可能受用户输入影响的导致sink的路径,这是漏洞的重要标志。
Java Web应用程序使用了两种不同类型的Web参数:(1)数据绑定参数,它由Web框架直接从请求绑定到入口方法的参数;以及(2)运行时绑定参数,通过 request.getParameter 等API进行动态检索和处理。WDFUZZ首先对Web入口方法的数据绑定参数进行污点处理。对于类类型的参数,WDFUZZ递归地污点它们的域,包括从超类继承的域。此外,当WDFUZZ识别与运行时绑定参数检索相关的调用站点时,它会污染相应的返回值。然后WDFUZZ通过过程间控制流图(ICFG)传播污点,寻找从web参数到sink位置的污点路径。当发现污点路径时,WDFUZZ还可以确定一条从入口到汇点位置的路径,其中汇点是由web参数潜在控制的。
为了提高污点分析的准确性,我们支持Java Web框架中常用的依赖注入特性。WDFUZZ为注入的类字段生成单例堆对象,并在调用图中连接相应的调用边准确地跟踪污点数据,从而增加了脆弱路径提取的可靠性。
Semantic Constraint Extraction
该模块的主要思想是根据处理参数的API操作序列提取语义约束。
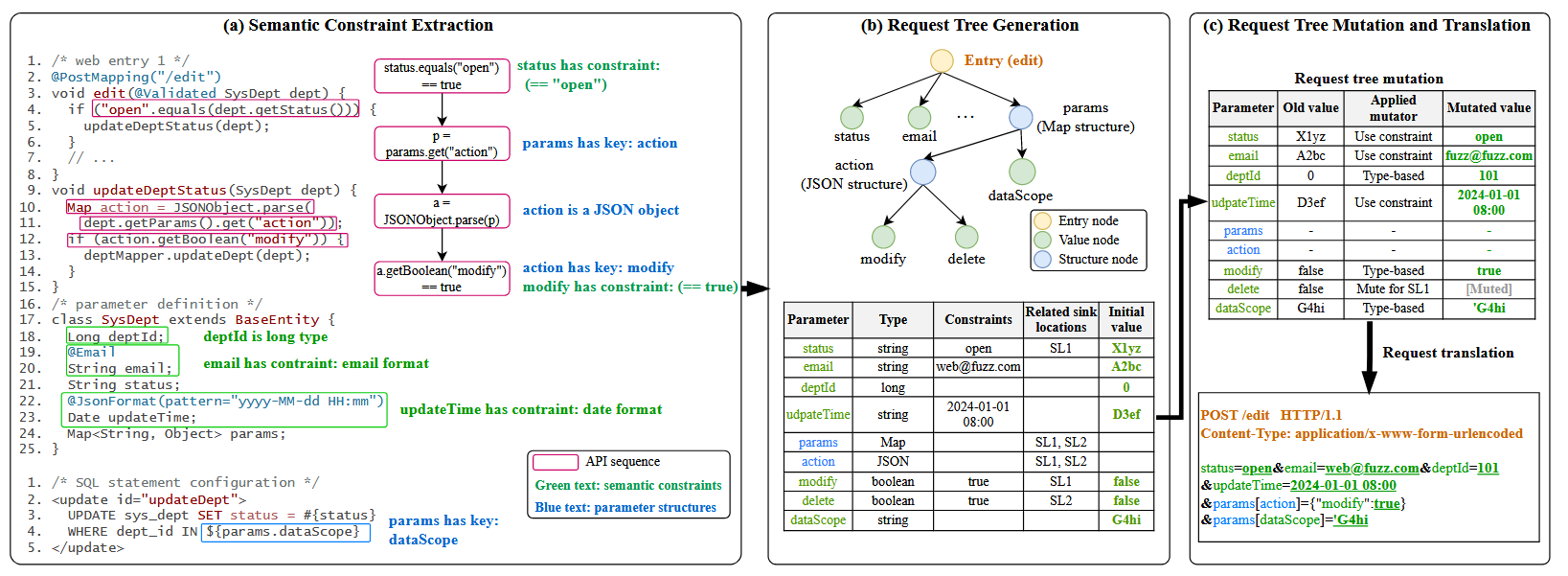
它首先根据网页参数的类型提取参数名称。对于直接映射到入口方法参数的数据绑定参数,WDFUZZ按照Java Bean约定对所有方法参数进行处理并提取其名称。为了提取运行时绑定参数的名字,我们在参数检索方法(e.g., request.getParameter)的参数上使用了一种后向数据流跟踪方法。这种技术允许我们回溯和识别正在传递和处理的参数名称。如图3所示,WDFUZZ可以识别出Web入口 edit 需要 SysDept 类中的5个数据绑定参数,即 deptId、email、status、updateTime和params。
在WDFUZZ识别出所有参数后,沿着4.1.2中找到的脆弱路径跟踪参数的污点路径。这种追踪允许WDFUZZ捕获处理这些参数的API序列,并提取语义约束,包括结构信息、类型约束和值约束。
(1)结构信息
通过分析API序列中参与参数结构处理的API来提取结构信息。例如,如果使用 JSON.parseObject 方法处理某个参数,WDFUZZ可以将该参数推断为表示JSON对象的字符串。进一步,如果下面的API调用是 obj.getString('some_key'),WDFUZZ可以推断该对象包含一个名为 some_key 的字符串类型的密钥。
(2)类型约束
类型约束是在分析API的基础上推导出来的,这些API在序列中隐含着特定类型的操作。例如,API序列中存在 Integer.syntaxInt,说明该参数应该是一个整数。此外,如果参数由类对象绑定,WDFUZZ根据域的声明类型推断参数类型。
(3)值约束
值约束是通过分析比较或验证参数值的API得到的。例如,如果一个参数通过 String.equal 等函数进行验证,WDFUZZ将求解常数值并将其提取为值约束。
以图3为例,WDFUZZ首先分析数据绑定的网页参数,提取语义约束。具体来说,它标识了参数 deptId 必须是一个long类型的值。此外,发现参数邮件和更新时间具有邮件和日期格式验证。WDFUZZ还检查配置文件,以获得关于Map类型参数 params 的结构信息。它揭示了在 params 中存在一个名为 dataScope 的key。
WDFUZZ进一步对 dept 参数及其字段进行污点跟踪,使其可以提取Web应用程序在该参数上执行的API调用序列,如图3的阶段(a)中洋红色部分所示。从这个API序列中,WDFUZZ可以揭示一系列与网络参数相关的结构和语义约束,例如,status 必须等于”open”;map类型的参数 params 包含一个命名为 action 的键;这个命名为 action 的键本身是一个嵌套的JSON对象,包含一个名为 modification 的键,其值必须为真值true。
Request Tree Generation
由于Web参数的树状特性,如嵌套的JSON和Map结构,WDFUZZ使用基于树的结构,即请求树,来表示Web应用每个入口点的初始种子。这样的结构可以包括提取的入口点、潜在的sink位置、参数名和语义约束的所有信息。一个请求树包括3种不同的节点类型,每种节点类型服务于不同的目的:
- 入口节点包含与入口点相关的信息,包括请求的URL、HTTP方法和总体参数传递方法(URL编码格式、JSON、XML等);
- 结构节点包含参数的结构信息,如Map或JSON对象中的键名。结构节点不包含具体值,而是作为层次占位符;
- 值节点存储键值对,其中键为参数名,值为该种子中参数的具体值。还包括前面静态分析模块提取的语义约束。
请求树的设计保证了每棵树都可以唯一地映射到特定的HTTP请求。
图3的阶段(b)显示了动机实例生成的请求树。请求树的结构由上一步提取的结构信息映射而来。树中的每个值节点还保留了关于约束和相关sink位置的信息,可以用于后期的变异。
Fuzzing Phase
模糊测试阶段旨在主动与Web应用程序接触,利用先前确定的入口点、sink和参数约束,通过一系列有针对性的突变和请求来发现漏洞。我们设计了一种分层调度来优先考虑最有希望的入口点和相应的sink位置,并利用一组变异算子来对请求树进行变异。以下几部分深入探究了具体的方法论。整个模糊测试循环总结在附录B中。
Hierarchical Scheduling
WDFUZZ利用分层调度来评估和选择Web应用程序中可能触发漏洞的最有前途的入口点和相应的sink位置。分级调度策略遵循一个综合评估过程,对最有希望的种子进行优先排序。首先,评估每个入口点触发漏洞的潜力,优先考虑具有更高潜力的入口点。随后,在选择Web入口后,还会评估所选入口到达特定sink位置的潜力,优先考虑更容易到达的位置。一旦确定了目标入口和sink位置,模糊能量(即突变的数量)从选择的入口和sink位置的语料中分配给种子。
为了方便这一点,设计了一种评分算法,根据入口点的潜力来计算评分,考虑了到sink位置的距离、入口点被调度的次数、呼叫站点被触发的次数以及入口点参数的复杂性等多个因素。sink位置的分数也是类似计算的。
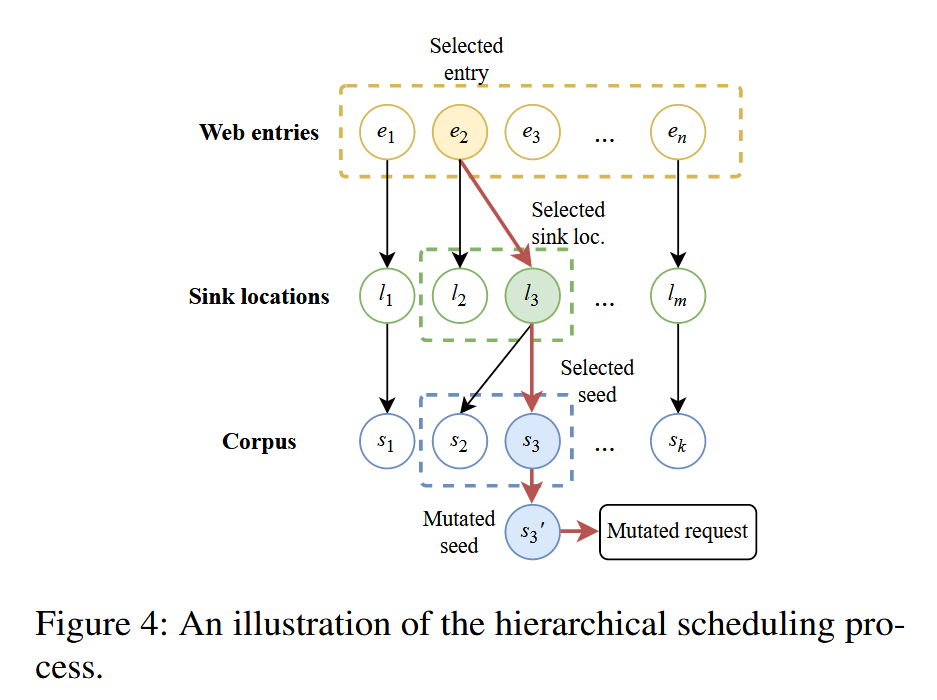
我们将这一调度过程可视化,如图4所示。首先,我们根据得分从所有入口点的池中采样一个目标入口点,例如图中所示的入口点 $e_2$。接下来,从所选入口对应的所有可达sink位置中,我们同样基于得分采样一个目标sink位置(e.g., $l_3$)。一旦确定了入口和sink的位置,我们从对应的语料库(一个FIFO循环队列)中采样下一个种子,如图中的 $s_3$,并分配其模糊能量,即为变异次数。然后将变异后的种子 $s’_3$ 转化为测试Web应用的请求。
评分算法是我们分级调度策略的关键组成部分,旨在使用多个参数评估每个入口点和相应sink位置的”有希望”性质的水平,从而最大限度地提高触发漏洞的效率。现有的评分算法,例如,Hawkeye[18],LOLLY[32]和SelectFuzz[34],通常专注于模糊测试单个入口,以触发特定代码位置的已知漏洞。相反,正如3.1所强调的那样,WDFUZZ评分算法的设计目标是高效地探索具有大量Web入口和sink位置的Web应用程序的大代码空间。综上所述,我们提出的评分算法有望提供两个独特的优势:
(1)它利用了Web应用程序固有的层次结构,认识到不同的Web入口、sink位置和参数具有不同的触发漏洞的潜力;
(2)此外,它还考虑了更广泛的Web特有的因素,以实现高效和有效的模糊测试,例如,Web参数的复杂性。
遵循上述设计考虑,我们的打分算法在技术上优先考虑那些与sink位置距离较低的种子,较少的调度,较少的sink位置到达次数和较低的复杂度。具体来说,一个入口点 $e$ 的得分定义为
$$s_e=-\bar d_e-\alpha n_{se}-\beta n_{te}-\gamma n_{ce}-\delta_e\tag{1}$$
其中 $\bar d_e$ 表示入口 $e$ 到所有可达sink位置的当前平均距离,$n_{se}$ 表示入口 $e$ 被调度的次数,$n_{te}$ 是入口 $e$ 成功触发sink位置的次数,$n_{ce}$ 是入口点 $e$ 的复杂度因子,定义为可变值节点的平均数量。
距离 $\bar d_e$ 最初是通过平均从入口点 $e$ 到每个可达sink的基本块的数量来计算的。在模糊测试过程中,每当一条执行路径到达一个基本块时,就会更新距离,从而减少到达任何sink所需的基本块数量。系数 $\alpha$、$\beta$ 和 $\gamma$ 通过经验设定来微调评分,$\gamma_e$ 是对那些已经触发bug预言的条目的惩罚因子。这种多维度的评分可以在探索和利用之间取得平衡,确保模糊器优先考虑最有前途的网页条目。
在评分之后,根据评分进行加权采样过程。这保证了在模糊处理过程中优先考虑得分较高的入口点。采样时使用的权重定义为
$$w_e=f(t)\exp(s_e)\tag{2}$$
其中 $f(t)$ 是一个时间系数,随着时间 $t$ 从0增加到1,使得分数的影响随着时间的推移而增长。例如,可以使用sigmoid函数:
$$f(t)=\frac{1}{1+e^{-k\left(t-\tfrac{t_0}{2}\right)}}\tag{3}$$
其中,$k$ 控制了时间系数增长的陡峭程度,${t_0}$ 表示 $f(t)$ 趋近于1的时刻,说明采样过程充分利用了评分结果。
一旦入口点采样完成,WDFUZZ基于类似的打分过程,进一步计算从所选入口点可以到达的每个sink位置的得分。sink位置 $l$ 的得分 $s_l$ 可以用类似于方程1来表示,采样sink位置的权重与方程2完全相同。
WDFUZZ为每一对入口点和sink位置维护一个语料库。当一个种子更新到相应的sink位置的距离或从入口点增加代码覆盖率时,该种子被添加到相应的语料库中。一旦WDFUZZ采样并确定当前要覆盖的目标入口点和sink位置,它基于先进先出(FIFO)循环队列从相应的语料库中依次检索种子。每个种子应该被变异和测试的次数,即它的能量,是根据AFLGo分数计算的[16]。一般而言,AFLGo评分会偏爱那些距离所选sink较近的种子,从而达到定向模糊测试的能力。在这里,我们采用了AFLGo score的原始版本,并对其进行了必要的实现定制,使其符合我们的模糊测试框架。具体来说,给定一个种子 $s$,它的AFLGo分数,记为 $p(s)$,由下面的公式计算得到
$$p(s)=p_{\mathrm{afl}}\cdot 2^{10p-5}\tag{4}$$
其中 $p_{\mathrm{afl}}$ 为标准AFL功率;$p$ 为基于退火的功率调度因子,由下面的公式计算得到
$$p=(1-\bar d)\cdot(1-T_{\exp})+0.5T_{\exp}\tag{5}$$
其中 $\bar d$ 为种子 $s$ 到所选sink的归一化距离。温度 $T_{\exp}$ 随时间从1逐渐减小到0,其定义为
$$T_{\exp}=\frac{1}{\left(1+19\cdot \dfrac{t}{t_x}\right)}\tag{6}$$
其中 $t$ 为模糊测试开始后的时间,$t_x$ 为探索时间,根据AFLGo的建议,探索时间设定为10分钟。
Request Tree Mutator
一旦种子被选中,WDFUZZ使用三个不同的变异算子来改变种子树结构中的具体节点,如下所示。
(1)约束值注入
该算子直接将提取的约束值应用于节点的实际值。如果节点具有值约束,则有概率突变将使用这些约束值中的一个。
(2)类型固定变异
这就涉及到根据节点的类型来创建节点值的随机变化。我们的变异策略是针对每一类值精心设计的。对于字符串值,WDFUZZ插入了逃逸字符和常见的有效载荷,如单引号,以测试SQL注入、路径遍历等常见漏洞。此外,我们还进行了常见的案例转换,以及随机的插入和删除,以进一步丰富输入变量。对于数值,WDFUZZ利用Benford’s Law[15]生成模拟数字自然分布的数值。我们还针对特定类型(如日期和布尔值)定制值变异过程,以生成随机值。
(3)类型改变变异
该变异算子随机改变一个值节点的类型,并基于新的类型生成新的值。这会导致输入结构的显著变化,在输入参数的处理过程中潜在地揭示与类型相关的脆弱性。
由于待测汇点位置是在突变前确定的,因此WDFUZZ将对与待测sink位置不相关的参数进行概率静音。这种方法有助于进一步缩小探索空间。图3中的阶段(c)说明了WDFUZZ如何利用上述算子对请求树进行变异,并将其翻译成具体的请求。
Implementation
WDFUZZ的实现分为不同的静态、动态和仪表组件,每个组件对模糊测试过程的整体效果都有贡献。对于静态准备阶段,我们将4.1中描述的各个模块作为Java程序分析框架Tai-e的插件来实现。静态分析构组件包括20.2k行的Java代码。
动态模糊组件建立在模糊测试框架libAFL之上。我们用4.7k行Rust代码和1.5k行的Python代码实现了4.2中的调度和变异策略。我们使用10个已知漏洞的数据集对分层调度技术的超参数进行了敏感性测试,以微调参数。实验中使用的最终参数设置为:$\alpha = 0.3,\beta = 0.3,\gamma = 0.3,\delta_e = 3$。
该工具有两个主要目的:反馈收集和bug预言。对于反馈,我们在脆弱路径的基本块中插入插桩,以使用Java代理提供距离信息。WDFUZZ的bug预言采用了两种检测策略:基于错误和基于调用。基于错误的方法,类似于witcher的故障升级,通过截获系统调用,如write,execve,并通过预加载共享库发送来捕获错误信息。但是,也确实存在一些异常或错误,这些异常或错误会在应用层(即Java层)被捕获,而在系统调用层无法被观察到。因此,也有必要使用Java方法来监控其运行时参数是否被恶意输入所控制。考虑到上述情况,WDFUZZ引入了一个基于调用的预言机,该预言机使用敏感的Java方法和异常构造函数来检测攻击者控制的参数值。例如,为了识别任意文件读写方法漏洞,WDFUZZ通过检查Java文件APIs(e.g., File.<init>)的参数来检查Web应用程序是否打开了输入Web参数中指定的任意文件。我们的bug预言机制支持广泛的漏洞检测,包括SQL注入、命令执行、任意文件读写方法、SSRF和SSTI。仪器组件包括4.7k行Java代码和430行C代码。
Evaluation
RQ1:在漏洞检测能力方面,WDFUZZ如何与最先进的web fuzzer,即witcher进行比较。为了评估WDFUZZ的漏洞检测能力,我们将WDFUZZ与witcher在来自不同Java Web应用程序的真实漏洞的基准数据集上进行了全面的比较。
RQ2:WDFUZZ能否识别先前未知的真实世界漏洞。该评估涉及将WDFUZZ部署在各种应用程序上,以检测先前未知的零日漏洞,从而证明其在实际场景中的有效性。
RQ3:WDFUZZ各组成部分对其整体性能的贡献程度如何。本研究问题旨在分析WDFUZZ的各个组成部分,即脆弱路径提取模块、语义约束提取模块和分层调度算法,以评估它们对整体有效性的贡献。
Dataset Construction
为了令人信服地评估WDFUZZ的有效性,我们选择了具有代表性和流行度的Java Web应用作为我们的评估对象,主要包括开源的和闭源的商业应用。对于开源应用程序,我们考虑了由开源社区主动维护的流行的Java Web应用程序。具体来说,我们最终选择了11个在GitHub上拥有超过2000颗星的应用程序,这表明社区的兴趣和使用程度很高。值得注意的是,这些应用程序都是使用WDFUZZ提供技术支持的通用Web框架实现的。在封闭源应用方面,我们考虑了3个目标应用,它们都是使用常见的Web框架开发的,并且公开披露了漏洞。此外,为了进一步提高目标应用的多样性,我们还纳入了WebGoat项目[4],这是一个有意策划的用于安全培训的易受攻击应用。
考虑到上述15个目标应用,我们进一步整理了影响这些应用的已知漏洞的稳健数据集。具体来说,我们在CVE数据库上进行了广泛的搜索,并收集了所有公开披露的漏洞。我们尝试手工复制这些漏洞,那些可以成功复制的漏洞都包含在我们的数据集中。总的来说,我们的数据集包括68个已知漏洞,包括各种漏洞类型,如SQL注入,命令注入,任意文件读写方法,SSRF和SSTI。
Result Overview
我们在数据集上对WDFUZZ进行了评估,以回答前面提到的研究问题。在漏洞发现能力方面(5.3),WDFUZZ取得了92.6%的召回率,比witcher多3.2倍。关于脆弱性再现的暴露时间,WDFUZZ与witcher相比,时间减少了87.69%。此外,漏洞发现效率是witcher的7.1倍。
在发现真实Web应用中的未知漏洞方面,WDFUZZ已经发现了92个先前未知的漏洞(5.4)。我们负责地报告了所有的漏洞,迄今为止已经有19个漏洞得到了供应商的确认和修复。此外,消融研究表明,WDFUZZ的每个模块都对Web漏洞检测的有效性做出了积极贡献(5.5)。
RQ1: Reproducing Known Vulnerabilities
为了评估WDFUZZ的漏洞检测能力,我们在5.1中描述的已知漏洞数据集上进行了一系列实验。根据witcher中的建议,为每个待测入口点分配2分钟的模糊测试时间预算。同时,我们为witcher提供了我们对攻击面识别的静态分析结果,因为我们发现其爬虫识别的入口点太少,无法获得有意义的比较结果。因此,在我们的对比实验中,我们实际上改进了witcher原有的方法。
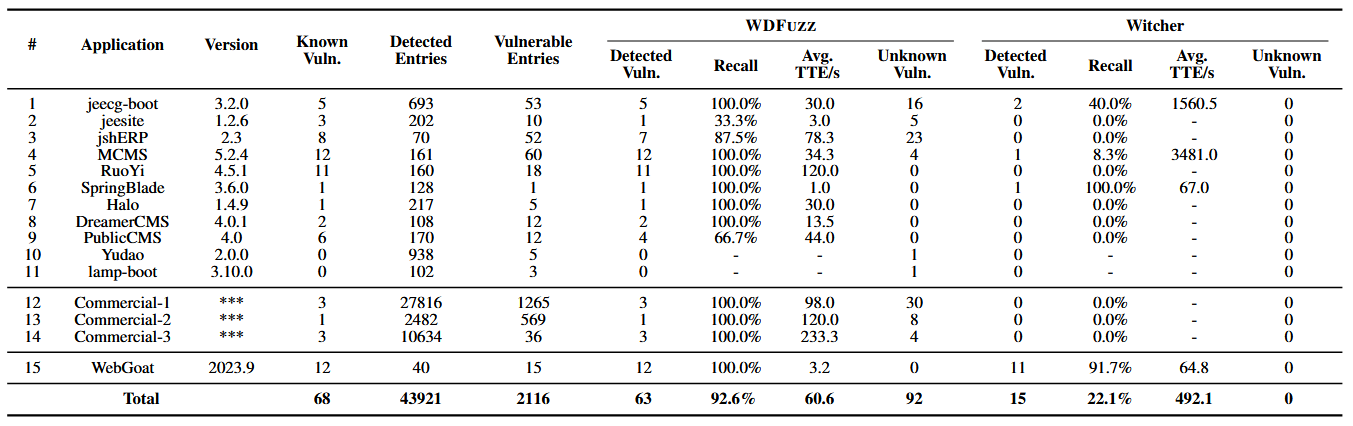
一目了然,如表1所示,脆弱路径提取技术将43921个待测入口点的初始池减少到仅有4.8%的词条(2116),显著缩小了Web应用的搜索空间。
对于已知漏洞的召回,WDFUZZ成功识别出92.6%(63/68)。相比之下,witcher仅能发现15个漏洞,这意味着WDFUZZ展示了3.2倍的漏洞发现效率。我们分析了WDFUZZ遗漏的5个漏洞,发现这些漏洞都是高阶漏洞,需要依次触发多个网页条目才能被利用。WDFUZZ并不是专门用来检测高阶漏洞的,但我们相信它是一个很有前途的未来研究领域。
此外,我们比较了WDFUZZ和witcher漏洞的平均暴露时间(TTE)。如表1所示,WDFUZZ不仅发现了更多的漏洞,而且减少了87.69%的揭露已知漏洞所需时间。
最后,我们通过测量每小时发现的漏洞数量来评估整体的漏洞发现效率。WDFUZZ每小时可识别59.39个漏洞,7.1倍快于witcher。
总之,这些发现证明了WDFUZZ在有效性(发现更多漏洞)和效率(更快的发现漏洞)方面都优于现有的最先进的web模糊测试。
RQ2: Identifying Unknown Vulnerabilities
如表1所示,WDFUZZ成功识别出92个先前未知的漏洞。这些漏洞存在于高风险类别中,包括83个SQL注入、4个SSRF、4个任意文件读写和1个SSTI,它们构成了包括敏感数据泄漏、Web服务中断和操作系统潜在接管在内的重大威胁。相比之下,基准模糊器witcher没有报告这些漏洞中的任何一个。
我们采取了积极主动和负责任的方式,将所有发现的漏洞报告给相应的开发人员和利益相关者。截至目前,已有19个漏洞得到了应用开发人员的确认。在此,我们还分析了19个CVE/CNVD脆弱性的根源,如下所示。

根本原因1:参数直接串联(16/19)。在这些情况中,用户输入直接被串接成SQL查询、URL或其他敏感参数,从而导致注入漏洞。图5所示的脆弱性是这一根本原因的典型例子。
根本原因2:框架API的误用(3/19)。这个根本原因是由于框架API使用不当造成的。例如,在配置MyBatis框架时,如果开发人员使用 #{input} 将一个输入参数传递到一个SQL查询中,则该查询将由MyBatis提供的准备语句技术进行保护,从而安全地将输入参数化。但是,一些开发人员可能会在查询中错误地使用 ${input},使得MyBatis可以直接插入用户输入,从而导致SQL注入。
一个来自Lamp-Boot的真实世界案例研究。如图5a所示,该漏洞是由于page 方法的第8行中存在不安全的SQL语句级联造成的。该漏洞要求模糊器构造一个复杂的JSON载荷,其字段必须遵循特定的语义约束,如图5b所示。输入必须以这样的方式进行结构化,它与 PageParams 类绑定,model 是 BaseEmployeePageQuery 的一个实例。关键的是,要触发第12行中的SQL注入漏洞,model 对象中的 scope 字段必须精确地设置为字符串”1”,表示常量 BIND。
WDFUZZ的完整版本成功发现了该漏洞,而witcher未能检测到该漏洞。其主要原因在于Fuzzer能够准确地生成所需的嵌套JSON结构,同时还能满足对诸如 email、state、userId和orgIdList 等字段的语义约束,这些字段必须分别是邮箱地址、布尔运算、整数和JSON列表。此外,WDFUZZ还成功地提取了范围字段的约束并通过了应用程序的验证,从而有效地暴露了SQL注入。
RQ3: Ablation Studies
在我们的消融研究中,我们系统地评估了WDFUZZ中每个模块的贡献,通过增量地重新引入它们来评估它们对性能的影响。我们的方法涉及围绕三个核心模块构建实验:脆弱路径提取、语义约束提取和分层调度策略。通过分离这些模块,我们旨在量化它们对WDFUZZ整体有效性的单独影响。下面列出了详细的配置。
- WDFUZZb (baseline):该设置应用CrawlerGo[3],一个工业网络爬虫来查找入口和参数,用固定的调度策略模糊每个入口2分钟,作为消融研究的基线。
- WDFUZZe (入口提取):该配置使用静态提取的无结构和约束信息的脆弱网页入口和参数,并在基线中应用固定的调度策略,来评估脆弱路径提取模块。
- WDFUZZc (约束提取):该变体包含参数结构和语义约束提取模块,以及固定的调度策略,用于评估语义约束提取模块如何影响漏洞检测性能。
- WDFUZZ (完整版):这个完整版本的WDFUZZ结合了所有的参数结构,约束提取和分层调度策略模块。
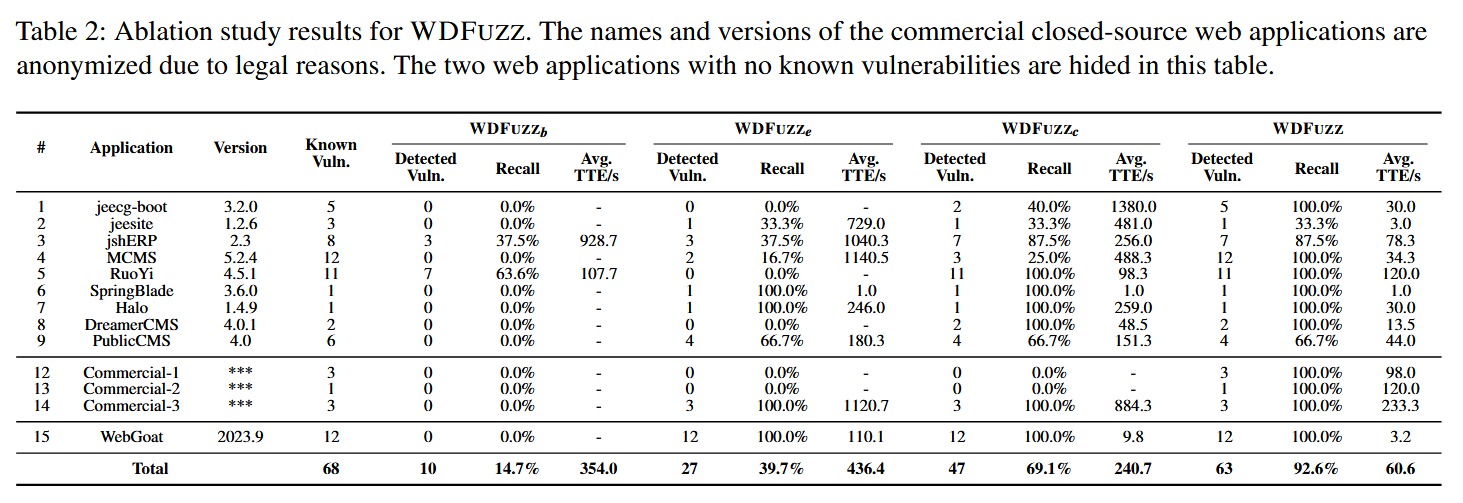
我们的消融研究结果汇总于表2。每个模块对已知漏洞的召回率都有显著的提高,提高幅度从20%到30%不等。下文的详细分析揭示了这些效率提升的内在原因。
首先,与基于爬虫的方法(WDFUZZb)相比,针对漏洞入口点提取的静态分析实现(WDFUZZe)显著扩展了攻击面,导致发现的漏洞数量增加了2.7倍。这种入口点和漏洞的增加必然导致更长的测试时间,每小时发现的漏洞数量略有下降,这是一种预期的权衡。
在入口点提取的基础上,我们通过结合参数结构和语义约束提取(WDFUZZc)进一步增强了模糊器的能力。这一修改导致漏洞发现增加了74.07%,同时总体TTE甚至略有下降。具体来说,每小时漏洞检测率提高了81.33%。产生这种效率的潜在原因是,借助参数结构和语义约束信息,模糊器可以生成更复杂的结构,如JSON格式,以及符合漏洞利用所需条件的值。因此,额外的约束有助于发现更深层次、更复杂的漏洞,同时也加速了浅层漏洞的识别。
此外,通过整合分层调度,WDFUZZ的完整版在发现漏洞数量上进一步提高了34.04%,同时TTE相应减少了66.24%。每小时漏洞发现率提高了2.97倍。这种增强是由分层调度策略贡献的,该策略首先将能量优先分配给最容易触发的漏洞。一旦这些漏洞被成功触发,调度算法将资源重新分配到目标更困难的漏洞上,从而确保这些具有挑战性的案例相比于固定调度方法获得更集中的测试能量。因此,分层调度策略能够更快地暴露更简单的漏洞,同时使用更多的资源测试复杂的漏洞,最终最大限度地提高漏洞检测的有效性和效率。
有趣的是,我们在若依应用(应用5)中观察到了一些反常现象。与入口点提取方法WDFUZZe相比,基线方法WDFUZZb产生了更多的漏洞数量。造成这种差异的原因是爬虫可以捕获前端预填充的少数嵌套结构,如 params[dataScope],而WDFUZZe方法由于缺少结构信息而无法生成这些嵌套结构。然而,值得注意的是,尽管爬虫能够偶尔发现某些结构,但其发现攻击面的整体能力仍然显著低下。因此,基于爬虫的方法检测到的漏洞数量远少于基于静态分析的方法。 此外,一旦我们结合了提取和生成复杂结构和约束的能力,WDFUZZ与基于爬虫的方法相比,显示出显著优越的整体性能,进一步强调了我们在漏洞发现方面增强的有效性。
Discussion
WDFUZZ的推广。虽然我们在Java中实现了WDFUZZ的原型,但是我们的方法可以很容易地适应其他编程语言。例如,在测试PHP Web应用程序时,可以简单地使用静态分析工具,如PHPJoern[13]和插桩工具,如Xdebug[8],从而替换原型中的工具链,以方便PHP应用程序的模糊测试。
高阶漏洞的检测。WDFUZZ目前不具备识别需要顺序触发各种Web条目来利用的高阶漏洞的能力。检测跨越多个入口点的源到汇流通常是一个具有挑战性的问题。因此,本文重点研究单个请求所能触发的漏洞。这类单步漏洞代表了所有已知漏洞的绝大部分,共92.6%。我们认为,检测高阶漏洞是一个巨大的研究课题,并认为它是未来研究的一个重要方向。
静态制备阶段的局限性。由于静态分析固有的局限性,WDFUZZ的静态准备阶段不可避免地会报告一些不准确的结果。例如,为了在语义约束抽取的可伸缩性和精度之间取得令人满意的平衡,WDFUZZ通过只考虑它们的单次迭代来简化循环。因此,在分析包含复杂回路的验证函数时,可能会产生不准确的结果。此外,对于脆弱路径提取,WDFUZZ会遗漏一些具有复杂动态语言特征的脆弱路径(例如, Java中的反射和本地接口)。然而,评估结果表明,当前版本的WDFUZZ可以成功识别68个基准漏洞中的63个,这表明来自静态分析的错误结果的影响是有限的。在未来,WDFUZZ可以通过结合更先进的静态分析技术[29(Return of cfa)、35(Context sensitivity without contexts)、48(Learning abstraction selection for bayesian program analysis)]来增强。
Related Work
静态分析
静态分析技术旨在不执行程序的情况下,识别出源代码中从用户控制输入(源)到安全敏感操作(汇)的潜在脆弱路径。为了解决企业级Java Web应用中庞大且异构的代码库所带来的挑战,Wang等人提出了ANTaint[46],它使用惰性加载库API来构建大规模的调用图,同时动态地转换代码以支持各种Web框架。TChecker[33]进一步改进了静态分析方法,提出了一种上下文敏感的过程间污点分析方法,基于类型推断构建精确的调用图,并结合上下文选择算法来减少开销。然而,静态分析经常被高误报率所困扰,这导致了大量的人工努力来对报告进行双重检查。此外,这些技术通常无法生成实际的PoCs,限制了它们在漏洞检测和缓解场景中的可用性。
黑盒扫描
黑盒扫描方法不需要访问源代码,从外部角度分析Web应用程序。这些方法包括几种通用的漏洞扫描器,如Burp Suite[2],Wapiti[7]和OWASP ZAP[5],它们提供了全面的漏洞检测能力。此外,一些研究集中在测试RESTful API和利用OpenAPI规范来指导测试。另一种显著的方法,Black Widow[24],建立了一个Web应用导航模型,并向输入注入唯一标识符,通过页面间的依赖关系来检测跨站脚本(XSS)漏洞。 此外,Re Scan[23]作为扫描仪和Web应用程序之间的中间件代理,通过启用二次登录和页面关系发现等功能,增强了现有黑盒扫描仪的扫描能力。然而,黑盒技术面临着一些局限性,包括低覆盖率阻碍了对更深层次漏洞的探索,以及依赖复杂的前端交互来获取反馈。
灰盒模糊测试
灰盒模糊测试代表了一种混合方法,它结合了静态和动态分析的两个方面。例如,webFuzz[45]直接修改PHP文件获得覆盖率反馈,指导XSS漏洞的检测。CeFuzz[49]使用从入口PHP文件到已知漏洞位置的路径作为输入,并沿这些路径优先使用具有最绕过条件检查的种子。withcer[42]使用解释器工具在不同的Web应用程序语言之间提供覆盖率反馈和增强泛化性,同时使用错误消息作为bug预言。Atropos[28]使用PHP比较函数来获得期望的键值对作为反馈,同时提供了八个全面的缺陷预言。然而,现有的灰盒网络模糊测试存在一些不足,如黑盒爬虫的覆盖率非常低,与Web框架开发模式不兼容等。而且,基于覆盖率的反馈往往会导致对众多无关路径的探索,调度策略也是幼稚的,缺乏选择最优切入点以最大化漏洞检测效率的考虑。
Follow My Flow - Unveiling Client-Side Prototype Pollution Gadgets from One Million Real-World Websites
Abstract
原型污染漏洞通常会产生进一步的后果,如XSS和cookie操纵,这些后果是通过所谓的gadget实现的,即代码片段,这些代码片段会为了恶意目的而改变受害者程序的控制或数据流。由于控制或数据流的变化有时需要通过原型污染注入复杂的属性值来替换现有的未定义的属性值,而这些属性值可能在以前看不到或不能被现有的约束求解器解决,因此先前的工作在寻找原型污染gadget时面临挑战。
本文设计了一个名为GALA的动态分析框架,用于自动检测现实世界网站中的客户端原型污染gadget。关键见解是,将非漏洞网站上已有的定义值借用给未定义的受害者,从而引导属性注入流向gadget中的sink。
对100万个网站的GALA评估揭示了133个0day gadget。
Introduction
原型污染是一种相对较新的漏洞类型,它允许攻击者操纵受害者JavaScript程序的原型对象属性。这类漏洞在现实世界中普遍存在:先前的工作(Probe the Proto Measuring Client-Side Prototype)已经发现了数以千计的排名靠前的、易受攻击的网站。当存在原型污染(漏洞)时,其对恶意后果的利用通常是通过一个概念来实现的,称为原型污染gadgets,即以一个(原始未定义的属性)为起点,以一个后果相关的sink或另一个原始未定义的属性为终点的JavaScript代码片段。这些原本未被定义的属性被攻击者利用注入的值进行操纵,从而影响受害者程序的控制或数据流,以达到其恶意目的,例如XSS和Cookie Manipulation。
先前关于原型污染gadget检测的工作可以分为两种类型:静态和动态。一方面,Silent Spring是一种主要的静态方法(带有一些动态分量,以获得未定义值),它依赖CodeQL来检测服务器端Node.js运行时未定义属性和sink之间的数据流。然而,这种静态的方法存在大量的假阳性( false positive,FP )。因此,Silent Spring不得不借助人工分析来生成和过滤FP。此外,Silent Spring只检测单个但没有链式的gadget。
另一方面,研究人员提出使用动态方法来检测此类小工具。ProbetheProto是目前唯一的关于客户端原型污染及其gadget的研究,它采用预定义的payload作为属性值,这种属性值通常是刚性的,当这些属性值未知时,会导致gadget的遗漏。另一项工作,UoPF采用concolic执行来检测服务端Node.js模板引擎的链式gadget。UoPF将未定义的值标记为符号,并使用约束求解器进行求解,如Z3。然而,现有的求解器无法扩展到复杂的约束,往往无法在有限的时间内提供有效的解决方案。UoPF在客户端小工具上的应用也是未知的,因为需要开发一个客户端协同执行框架。
本文设计了一个名为GALA (Gadget Locator和Analyzer)的动态分析框架,用于在一百万个真实网站中检测客户端gadget。关键见解是,有些属性在某些网站上是没有定义的,而在其他网站中也有相应的定义值,用于不同的功能,这些定义值流向sink。因此,GALA可以根据定义的值和它们的流来定位一个gadget,并引导敌手注入的值(替换原来未定义的)流向sink进行利用。也就是说,GALA解决了先前的工作(它们要么没有预定义的值,要么不能使用约束求解器产生一个值)使用其他网站中的定义属性为受害者网站的未定义属性定制复杂值的挑战。
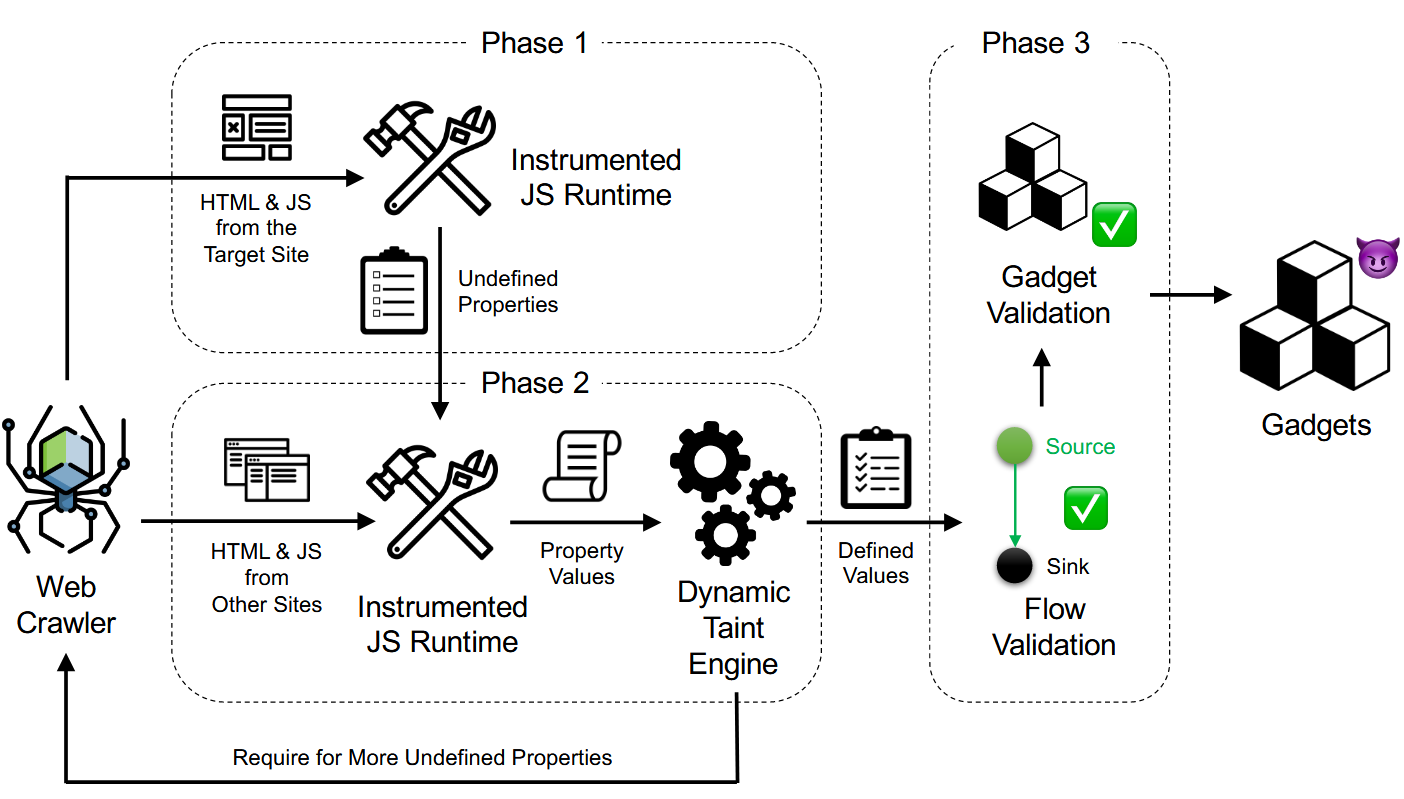
自然地,GALA有三个阶段:(i)定位未定义的属性,(ii)为先前未定义的属性分配定义的值,(iii)使用定义的值引导未定义的属性。具体来说,首先,在”未定义定位”阶段,GALA使用Chromium的修改版本对目标网站进行渲染,以记录所有未定义的属性。其次,在”定义分配”阶段,GALA为第一阶段发现的未定义属性定位定义值,并跟踪这些值是否流向sink。最后,在”引导”阶段,GALA使用定义的值来引导未定义的属性注入。这样的过程可以重复进行,因为在数据流中可能会发现额外的未定义的属性。
本文实现了GALA的一个开源原型,并在Tranco列表的一百万个网站上运行。结果揭示了133个在以前的工作中没有发现的零日gadget,包括一个来自Meta维护的软件的零日gadget和另一个来自Vue框架的零日gadget。还利用1000个网站将GALA与ProbetheProto和Silent Spring进行了比较。评估表明,GALA检测到了ProbetheProto和Silent Spring发现的所有gadget。此外,GALA发现23个具有原型污染漏洞的网站-这些网站被先前的工作报告为没有进一步的后果,特别是ProbetheProto-更容易受到包括XSS和Cookie/URL操纵在内的后果的影响。
Overview
Background
原型污染允许敌手遍历原型链-如果一个对象查找是可控的-然后在一个原型对象下注入一个恶意的属性。一个典型的目标将是一个内置对象的原型,例如Object.prototype和Function.prototype,因为它们是许多其他JavaScript对象的基础对象。因此,对原本未定义的属性查找的后续查找可能会导致敌手注入的值和控制或数据流的改变。根据控制流或数据流向不同汇的变化,攻击者可能通过所谓的gadget将原型污染升级为不同的后果,如服务器端的远程代码执行(Remote Code Execution,RCE)和客户端的XSS。更具体地说,一个原型污染gadget,遵循先前的工作,被定义为一个代码段,从一个未定义的属性开始,以一个汇或另一个未定义的属性结束。如果一个gadget从一个未定义的属性开始,并以一个sink结尾,则该gadget被称为直接gadget;否则,如果一个gadget需要一些未定义的属性才能最终到达sink,则将gadget列表定义为一个gadget链。
A Motivating Example
这部分描述了GALA发现的一个真实世界的零日原型污染gadget。gadget位于Meta开发和维护的软件中,名为”fbevents.js”,负责向Meta发送网站访问者数据。该gadget的后果被称为Cookie操纵,即敌手控制的Cookie的注入和更改。
下图展示了这个零日gadget的源代码。b[0] (第5行)最初是未定义的,因此由敌手通过原型污染来控制。注入的值流向第16行,最终流向第17行,影响document.cookie。该gadget在21个真实网站中导致了Cookie操纵的后果。由于这是一个跟踪cookie,敌手可能会像会话固定一样劫持具有自身价值的cookie,从而可能窃取受害者未来的访问历史记录,或者向受害者注入自己的访问历史记录,在目标网站上冒充受害者。这一结果也被Meta承认为补丁和bug奖赏的部分原因。补丁代码如第7行所示,检查0属性是否本地化为b,而不是原型对象。

虽然gadget看起来很直观简单,但由于其复杂的约束(第11~13行),现有的检测和利用gadget的方法非常具有挑战性。具体来说,由于第11行将基于字符点的字符串值拆分为一个数组,而第12行将数组的长度检查为4,所以利用中的值需要包含3个点。让我们看看为什么最先进的方法不能检测和利用它。首先,ProbetheProto-检测客户端gadget的唯一工具-未能满足Line11-13的约束,因为它使用预定义的值,例如通常使用的XSS载荷和用于Cookie操作的随机字符串。其次,即使先前对服务器端小工具的工作-如UoPF和Silent Spring-可以假想地移植到客户端,它们也无法检测和利用gadget。一方面,现有的约束求解器,例如Z3,不支持复杂的字符串操作,例如分裂。另一方面,客户端代码大量使用动态特性,这往往会导致现有的静态分析失效。
相反,GALA可以检测和利用gadget,因为b[0]是在其他网站中定义的,其具体值包含三个点。具体来说,这个具体的值来自于这些网站的一个cookie,命名为_fbc。即这些网站使用正则表达式读取此cookie,存储到数组b中,更新cookie,最后写回document.cookie。作为比较,受害者网站没有_fbc cookie,因此b[0]是未定义的。GALA从那些被定义为污染受害者网站和检测gadget的网站中借用了b[0]的值。
Threat Model
我们的威胁模型假设原型污染脆弱性的存在,然后敌手定位gadget以利用原型污染造成进一步的后果。如果一个未知的原型污染确实与一个gadget一起存在,我们称之为端到端的利用。否则,我们称这个发现为gadget,如果这个gadget在之前是未知的,并且不能被之前的工作检测到,则称为零日。我们的in-scope结果与之前关于客户端gadget的工作相同,并列举如下:
- 跨站脚本(XSS)。攻击者污染了一个原型对象,这样被污染的值可以作为JavaScript执行,例如,通过eval和innerHTML。
- Cookie操作。攻击者污染的值可以操纵受害者网站的cookie jar,例如通过document.cookie。
- URL Manipulation。攻击者可以操纵给定URL的查询字符串,这可能导致类似HTTP参数污染的攻击。
值得注意的是,除了原型污染漏洞之外,对gadget的检测也是必不可少的,就像对内存相关漏洞的gadget检测一样。一方面,一个带有gadget的网站目前可能不会受到原型污染的影响,但如果在未来包含一个具有原型污染的脚本,则可能会变得脆弱。另一方面,攻击者可能会篡改已知gadget的数据库,并利用这些gadget进行原型污染。
以下问题不属于本文的研究范围。
- Server-side Gadgets。服务器端的后果,例如命令注入,这类gadget的检测不在本文的范围之内,因为GALA分析的是顶级网站,而不是服务器端的包。可以参考先前的工作,例如,UoPF和Silent Spring,用于检测服务器端gadget。
- 原型污染的检测。我们认为原型污染漏洞本身的检测和利用不在论文的范围之内,因为我们主要关注原型污染的后果,即gadget的检测和利用。可以参考以前的工作例如,ProbetheProto,用于检测技术。值得注意的是,论文中考虑了端到端的利用,使用ProbetheProto检测到的原型污染和GALA检测到的零日gadget。
Design
System Architecture